Get full visibility into all aspects of IIS web server performance. Monitor all web sites, user accesses, get alerts on slowness, errors and traffic surges. Proactively detect and fix issues fast, before users notice.
Trusted by leading companies


Microsoft's Internet Information Server (IIS) plays a pivotal role in supporting web applications on Microsoft Windows operating systems. Using a thread-per-request processing model, Microsoft IIS offers a scalable way of supporting web sites and applications. While IIS is widely used to host ASP.NET web sites and applications, it can also be the front-end for other applications based on Java, PHP, etc.
In a multi-tier architecture the front-end IIS web server handles all the information relating to user activity, accesses, errors, and security events and so any slowdown in the web server tier will adversely affect the entire application's performance and ultimately, the user experience.
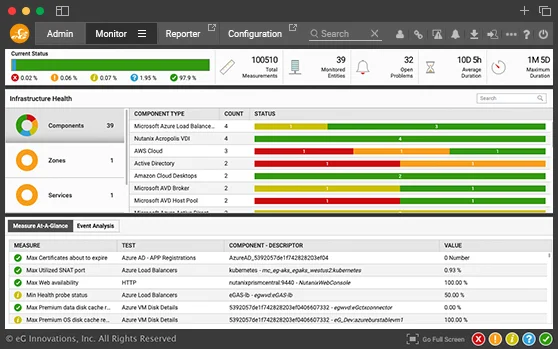
eG Enterprise is the ideal real-time IIS monitoring software for diagnosis, and reporting for heterogeneous web server farms. Using a combination of active and passive monitoring eG Enterprise tracks the availability and performance of the web applications and pinpoints where performance bottlenecks lie in the web server, middleware, database, virtualization platform, storage, etc.
It becomes complex for IIS monitoring tools to monitor IIS web servers due to:


With eG Enterprise's full stack monitoring capabilities, keep your IIS-based web applications working well.
With eG Enterprise, we can now quickly identify root causes of incidents, resolving them before users are impacted. Automatic prioritization and categorization of alerts helps us better focus on the important issues and prioritize our resources accordingly.![]()




| External monitoring |
|
| Internal web transaction monitoring |
|
| IIS Web site monitoring |
|
| Bottleneck detection |
|
| Capacity planning |
|