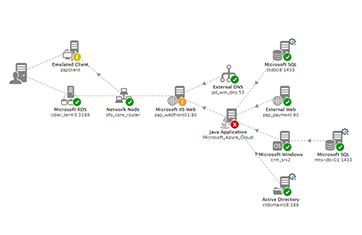
When an incident happens in an IT infrastructure or relating to an IT application, IT operations teams receive a number of alarms. Each alarm provides details of an abnormality in the IT infrastructure or with the application. Examples of alarms could be high CPU usage on a server, many blocked threads in an application, slow responses from the database, etc. To be able to troubleshoot issues, IT teams need to be able to set priorities for alarms, so they can focus on the highest priority alarms first.
If priorities are assigned to alarms, this allows IT operations teams to be efficient. The highest priority is often assigned to alarms that have the highest severity (e.g., are service impacting – a web service is down) and low priority is assigned to proactive alarms (e.g., ones that indicate a potential future problem – a memory leak in an application). By focusing on the highest priority problems first, IT teams can reduce mean time to repair (MTTR).
Alarm priorities can be set manually, depending on the type of metrics. E.g., a response time alarm is probably more severe than an alarm highlighting that memory on a server is highly utilized. Monitoring tools like eG Enterprise have out of the box configurations where the priority of alarms is set based on the type of metric they relate to.
Alarm priorities can also be set on the value of a metric. For example, if disk space utilization is 90%, an IT admin may want a low priority alarm. If the utilization moves to 95%, the alarm should be raised to a medium priority, and when the utilization reaches 99%, the alarm should be moved to a high/critical priority.
At the same time, when multiple high priority alarms are detected, it is important to further classify which alarms have to be acted upon immediately. This is where alarm correlation comes in. Alarm correlation analyzes multiple alarms that have the same severity and then determines which ones are indicative of the root-causes of problems. Alarms that indicate the root-cause of problems are retained at higher priority levels, while those that relate to the causes of problems are moved to lower priority levels.
Intelligent alarm priority management is a key to reducing mean time to repair (MTTR) and enhancing IT service performance. Monitoring tools like eG Enterprise embed alarm correlation and root-cause diagnosis capabilities that help automatically set alarm priorities.
IT monitoring tools must have:
When choosing a monitoring tool, it is important to evaluate how it handles a change in the value of a metric that has triggered the alarm alert. Consider CPU on a server, you may want a value of 90% consumed to trigger a minor alarm or warning level alarm, a value of 95% consumed to trigger a medium level alarm and a value of 97% to trigger a high level or critical alarm.
In some systems, each of these alarms need to be configured individually and so an administrator will receive multiple alerts if the CPU usage rose from 80% to 99% over a period of time. In more modern monitoring tools, multiple thresholds and priorities can be associated with a single alert and the system will handle the escalation or de-escalation of the alarm priority as the value of the metric on which the thresholds are set changes.