Trusted by leading companies


Amazon Aurora is a relational database engine that is MySQL and PostgreSQL compatible and can be run on RDS or Aurora Serverless. Aurora’s innovative architecture decouples storage from compute and delivers higher performance compared to MySQL (up to 5 times) and PostgreSQL (up to 3 times). However, this performance requires Aurora to be configured and managed correctly.
Monitoring is an important part of maintaining the reliability, availability, and performance of Amazon Aurora and your AWS applications. As Amazon outline, monitoring Aurora requires you to correlate and integrate metrics and events from several sources within your AWS environment. Native AWS tools and CloudWatch monitoring require users to manually configure any thresholds and alerting needed and manually correlate alerts. Native AWS monitoring is also prohibitively expensive at scale.
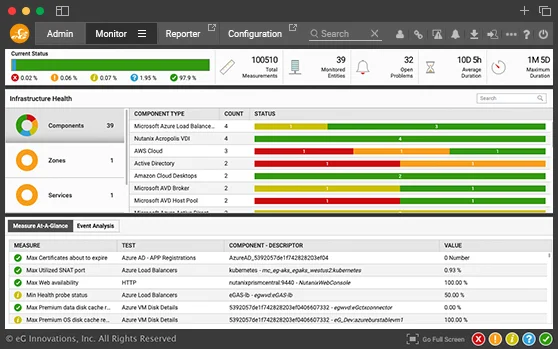
AIOps-powered eG Enterprise provides cost-effective, end-to-end, out-of-the-box proactive monitoring for Aurora and its dependencies. eG Enterprise provides continual 24/7 Aurora monitoring with both real-time and historical analysis to help you catch the earliest warnings signs of performance issues as soon as they arise and before users and services are impacted. Metric thresholds and alerting are set up ready-to-go and AIOps powered baselining provides intelligent anomaly detection avoiding alarm storms.
As a solution chosen for high-availability and performance, comprehensive monitoring is essential for those working with Amazon Aurora. eG Enterprise AIOps-powered observability platform supports the monitoring of both MySQL and PostgreSQL variants of Aurora. eG Enterprise monitoring helps resolve common challenges with Aurora, including:
Continual monitoring of metrics, logs and traces keeps applications running smoothly. eG Enterprise allows you to understand and track key performance data such as:
Learn more about eG Enterprise’s detailed monitoring capabilities for MySQL and PostgreSQL technologies.
eG Enterprise supports over 650+ different technology stacks to monitor end-to-end performance and application delivery in infrastructures spanning hybrid, multi-cloud and on-premises services and hardware.
eG Enterprise provides visibility into all aspects of Aurora database performance - workload, configuration, memory buffers, I/O operations, queries, deadlocks, etc. It auto-correlates database performance with that of the underlying AWS infrastructure - operating system, virtualization and storage tiers, automates and accelerates the discovery and diagnosis of database performance issues.
Rich and broad support for Amazon AWS services and cloud allows you to monitor all your AWS subscriptions and billings in addition to their performance. Allowing you to understand cost optimization choices based on data.
eG Enterprise’s comprehensive database support for all major database technologies and services allows you to monitor and baseline database usage within migration projects and to compare Amazon Aurora vs DynamoDB and various other technologies including Snowflake, AWS RDS, and more.
All in a single unified console.
Aurora databases can be set up quickly, and applications are configured to access Aurora databases using existing code, drivers, and programs with minimal changes thanks to its compatibility with MySQL and PostgreSQL. Aurora is designed for fault tolerance, availability, and storage elasticity and can be set up with cross-region read replicas.
Amazon Aurora is designed to be a high-performance database service, with features such as read replicas, automatic backups, point-in-time recovery, and multi-AZ (Availability Zones) deployment for high availability. It uses a distributed, fault-tolerant architecture, with storage spread across multiple availability zones in a region, and it automatically replicates data across multiple storage nodes for high durability and performance.
One of the main benefits of Amazon Aurora is its scalability. It allows users to scale their database instances up or down depending on their needs, with the ability to add up to 15 read replicas for better performance.
Amazon Aurora is compatible with various AWS services, including Amazon CloudWatch, AWS CloudFormation, and AWS Identity and Access Management (IAM), which makes it a popular choice to integrate into existing AWS environments.
Amazon Aurora, Amazon RDS (Relational Database Service), and Amazon DynamoDB are all cloud-based database services offered by Amazon Web Services (AWS), but they have different use cases and features.
The choice between AWS DynamoDB vs Aurora vs RDS, depends on the specific requirements of your application. The choice between AWS DynamoDB vs Aurora vs RDS, depends on the specific requirements of your application. If you need a relational database and high compatibility with existing systems, RDS is a good choice. If you need a highly scalable, highly available, and highly durable NoSQL database, DynamoDB is a good choice. If you need a high-performance, low-latency, and high-throughput database, Aurora is a good choice.
Read more about the differences and typical use cases in this article, Aurora vs DynamoDB vs RDS: Comparing AWS Database Types (eginnovations.com).
Native cloud monitoring tools such as CloudWatch suffer from the weakness that if AWS is down administrators lose visibility and customers using your applications dependent on AWS services will call you. eG Enterprise has a number of features included to ensure your ITOps are resilient even during AWS or Aurora outages. See: How to Protect your IT Ops from Cloud Outages (eginnovations.com).
Amazon Aurora has a billing and pricing model based on the amount of database resources consumed by your Aurora cluster, as well as any additional features or services you may use. Pricing differs for MySQL vs. PostgreSQL compatible editions.
The pricing for Aurora includes two main components: compute and storage. The compute component is based on the number and type of database instances you use, while the storage component is based on the amount of data stored in your Aurora cluster. You are charged hourly for each of these components based on the usage.
There are also additional charges for using features such as cross-region replication, backup storage, and data transfer. The pricing for these features varies depending on the specific service used and the amount of data transferred or stored.
You can find detailed information about the pricing of Aurora on the AWS website, including a pricing calculator that allows you to estimate the cost of using Aurora based on your specific needs and usage patterns. See: Amazon Aurora Pricing | MySQL PostgreSQL Relational Database | Amazon Web Services.
These pay-as-you-go (PAYG) and pay-as-you-use models mean that using a tool such as eG Enterprise can help you optimize your Aurora costs and ensure you are using the most cost-effective solutions for your use case. eG Enterprise can also provide you with automated alerting on abnormal usage and billing costs to avoid unexpected and unnecessary expenses.