
The Apache Hadoop Java software library is an open-source framework enabling the distributed (and parallel) processing of extensive datasets across computer clusters using straightforward programming models. It is built to scale from a single server to thousands of machines, each providing local computation and storage. Instead of depending on hardware for high availability, the library is designed to detect and manage failures at the application layer, thereby providing a highly available service on a cluster of computers, each of which may experience failures.
Hadoop is designed to handle large datasets; in many real-world use cases these datasets often range in size from gigabytes to petabytes of data.
Hadoop consists of the following core components:
Hadoop Distributed File System (HDFS): HDFS is a Java-based system that allows large data sets to be stored across nodes in a cluster in a fault-tolerant manner. HDFS allows you to store data of various formats across a cluster. It creates an abstraction layer, similar to virtualization. You can see HDFS logically as a single unit for storing data, but you are storing your data across multiple nodes in a distributed fashion. HDFS follows master-slave architecture.

Figure 1 : The HDFS architecture
In HDFS, NameNode is the master node and DataNodes are the slaves. NameNode contains the metadata about the data stored in DataNodes, such as which data block is stored in which DataNodes, where are the replications of the data block kept etc. The actual data is stored in DataNodes.
The data blocks present in the DataNodes are also replicated for high availability; the default replication factor is 3. This means, that every data block will by default be replicated across three DataNodes. This way, if even one of the DataNodes fails, HDFS will still have two more copies of the lost data blocks in two other DataNodes.
Moreover, HDFS focuses on horizontal scaling. This way, you can always add more DataNodes to the HDFS cluster as and when required to expand its storage capacity, instead of scaling up the resources of your DataNodes.
Also, HDFS follows the WORM (write once, read many) model. Due to this, you can write the data only once, but you can read it multiple times for accessing or processing data. Data processing is also faster, as the different slave nodes process the data in parallel and then send the processed data to the master node; the master node merges the data received from the different slave nodes and sends the response to the client.
MapReduce: MapReduce is both a programming model and big data processing engine and framework for parallel and distributed processing of large datasets.
MapReduce divides a job into smaller tasks (Map tasks), processes them in parallel across the cluster, and then aggregates the results (Reduce tasks).
Originally, MapReduce was the only execution engine available in Hadoop. But, later on Hadoop added support for others, including Apache Tez and Apache Spark.
Yet Another Resource Negotiator (YARN): YARN performs all your processing activities by allocating resources and scheduling tasks.
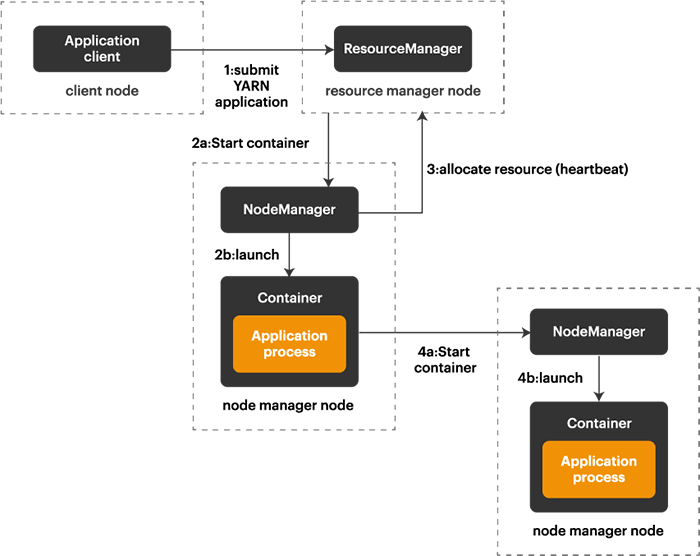
Figure 2: YARN architecture
ResourceManager is again a master node. It receives the processing requests and then passes the parts of requests to corresponding NodeManagers, where the actual processing takes place. NodeManagers are installed on every DataNode. It is responsible for the execution of the task on every single DataNode.
Hadoop Common: A set of common utilities and libraries used by other Hadoop modules.
Hadoop Common provides filesystem and OS-level abstractions, necessary Java libraries, and utilities for Hadoop modules to interact with the underlying operating system.
The term Hadoop is a general name that may refer to any of the following:
Apache Hadoop is not a database. It is an open-source framework designed for distributed storage and processing of large data sets across clusters of computers. Hadoop's core components include the Hadoop Distributed File System (HDFS) for scalable storage, MapReduce for parallel data processing, YARN for resource management, and Hadoop Common for supporting utilities. While Hadoop handles big data effectively, it does not offer the query capabilities of traditional databases. Instead, it integrates with tools like Apache Hive, which provides a SQL-like interface for querying data stored in Hadoop. Thus, Hadoop is a data processing framework, not a database.
MapReduce is a programming model and an associated implementation for processing and generating big data sets with a parallel, distributed algorithm on a cluster. A MapReduce program is composed of a map procedure, which performs filtering and sorting, and a reduce method, which performs a summary operation. It consists of two main functions: Map and Reduce.
Here is an example of how MapReduce works to generate the word count i.e. count the occurrences of each word in a large text file.
Map Phase:
Shuffle and Sort Phase:
Reduce Phase:
The result is the total count of each word in the text file, processed efficiently across multiple nodes in the Hadoop cluster.
Apache Hadoop is extensively used in real-world applications across various industries, including for search engines. In finance, it aids in risk management and fraud detection by analyzing massive transaction datasets. Retailers leverage Hadoop for customer behavior analysis and recommendation engines, enhancing personalized and targeted marketing. In healthcare, Hadoop processes genomic data and analyzes electronic health records to improve patient care. Telecommunications companies use it for network traffic analysis and customer churn prediction. Hadoop supports IoT data processing, enabling real-time analysis of high-volume sensor data.
An interesting collection of use cases is available, here: Hadoop Use Cases and Case Studies :: Hadoop Illuminated.
Yes, you can run Hadoop on public clouds. Major cloud providers offer Hadoop as a managed service, making it easier to deploy and manage. These include:
These services handle the complexities of cluster setup, scaling, and maintenance, allowing you to leverage Hadoop’s capabilities for big data processing in a scalable and cost-effective manner.
Hadoop is commonly used to power search engines, for processing logs, in data warehousing, and in video and image analysis. In short, Hadoop is widely used by business-critical applications where high availability and rapid processing of large volumes of data are key. Where such applications are in use, a processing bottleneck or a storage crunch on the Hadoop cluster can adversely impact application performance, causing user experience with the application to suffer.
To avoid this, administrators should monitor the availability, processing ability, space usage, and overall health of a Hadoop cluster. This is where eG Enterprise helps!
eG Enterprise provides a specialized model for monitoring Hadoop. This AIOps-driven, domain-aware model, alerts administrators to real and potential issues in the performance of the cluster and brings operational inconsistencies in the core components of the Hadoop architecture - e.g., DataNodes, NodeManager, ResourceManager etc. - to the notice of administrators. This way, eG Enterprise ensures the timely resolution of cluster-related issues, and thus paves the way for high uptime and peak performance of the Hadoop cluster.
eG Enterprise also monitors and correlates Hadoop ecosystem components such as Apache Hive, Apache Impala and Apache Zookeeper – plus over 500+ other application and IT technologies for full-stack and end-to-end observability.





