What is Apache Hive?
Apache Hive is a distributed, fault-tolerant data warehouse system that enables analytics at a massive scale. A data warehouse provides a central store of information that can easily be analyzed to make informed, data driven decisions. Hive allows users to read, write, and manage petabytes of data using SQL.
Hive is built on top of Apache Hadoop, which is an open-source framework used to efficiently store and process large datasets. As a result, Hive is closely integrated with Hadoop, and is designed to work quickly on petabytes of data. What makes Hive unique is the ability to query large datasets, leveraging Apache Tez or MapReduce, with a SQL-like interface.
The following component diagram depicts the architecture of Apache Hive:
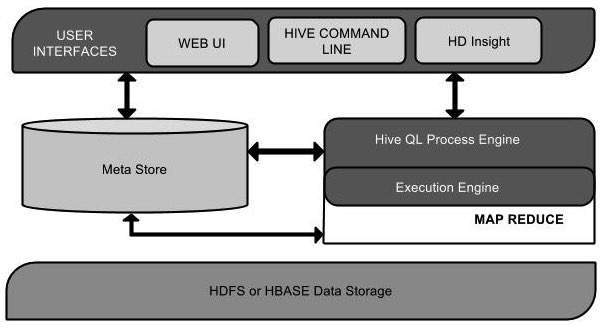
Figure 1 : Apache Hive Architecture
This component diagram contains different units as each of them are discussed below:
-
User Interface: Hive is a data warehouse infrastructure software that can create interaction between user and HDFS. The user that interfaces Hive supports are Hive Web UI, Hive command line, and Hive HD Insight (In Windows server).
-
Meta Store: Hive chooses respective database servers to store the schema or Metadata of tables, databases, columns in a table, their data types, and HDFS mapping.
-
HiveQL Process Engine: HiveQL is similar to SQL for querying on schema info on the Metastore. It is one of the replacements of traditional approach for MapReduce program. Instead of writing MapReduce program in Java, we can write a query for MapReduce job and process it.
-
Execution Engine: The conjunction part of HiveQL process Engine and MapReduce is Hive Execution Engine. Execution engine processes the query and generates results as same as MapReduce results. It uses the flavor of MapReduce.
-
HDFS or HBASE: Hadoop distributed file system or HBASE are the data storage techniques to store data into file system.
Why Monitor Apache Hive?
In mission critical environments, even the slightest of deficiencies in the performance of the data warehouse if not detected promptly and resolved quickly, can result in irredeemable loss of critical data. To avoid such data loss and to ensure availability of data round the clock, the Apache Hive should be monitored periodically. For this purpose, eG Enterprise offers a specialized Apache Hive monitoring model.
By closely monitoring the target Apache Hive, administrators can be proactively alerted to issues in the overall performance and critical operations of the Apache Hive data warehouse, identify serious issues and plug the holes before any data loss occurs.