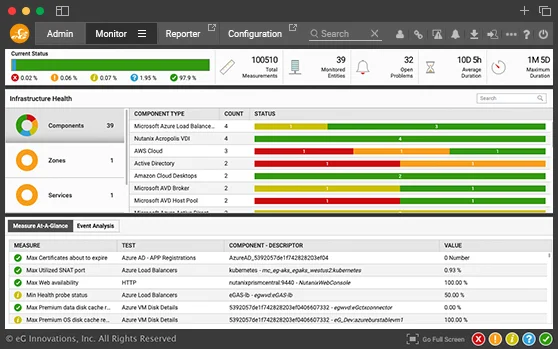
Automatically Safeguarded Performance Monitoring for Low Overhead Maintenance and Continuity Assurance
Free TrialTrusted by leading companies


In many domains, IT infrastructures have been transformed from being support structures to mainstream channels that drive the day-to-day business. While accurate and instantaneous notification of problems is important, it is even more critical that the monitoring system(s) that perform such diagnosis and notification are available 24*7, so no problem goes undetected or uninformed. The manager redundancy option for the eG management console ensures “fail-proof” availability of the eG management suite.
eG Innovations delivers a robust, reliable and extremely valuable solution to deliver maximum uptime and user satisfaction. Pre-emptive alerting helps us to address performance issues immediately before they affect system and application availability. ![]()

The redundancy option for the eG suite ensures that there is no single point of failure while deploying monitoring for a mission-critical infrastructure. In this approach, a redundant cluster is created by grouping multiple eG management consoles. One of the managers functions as the "primary" manager to which operators can connect to view performance statistics as well as to perform administration actions. Any administrative changes made on the primary manager are propagated in real-time to the “secondary” managers.
The eG agents can report to either the primary or the secondary managers, with the assignment of agents to managers being controlled through the web console. The agents are capable of dynamically discovering the redundant cluster configuration, thereby allowing for new managers to be brought in without needing to perform elaborate reconfiguration of the agents.

When one of the managers in a cluster is down, the agents automatically start reporting to one of the other managers in the cluster. At any point, an agent reports to only one of the managers in the cluster. The managers in the cluster are responsible for replicating performance data between them.
This architecture ensures that there is no additional overhead on the agents for supporting the redundant configuration of managers. All the performance statistics received by one of the managers in the cluster is replicated to the other managers in the cluster. This ensures that the secondary managers act as active standbys for the primary manager. In the event of any failure of the primary manager, users can connect to any of the secondary manager to view real-time and historical performance statistics.
Temporary storage of metrics by each of the managers ensures that there is no data loss in the cluster even though one or more of the managers in the cluster may have gone down for a while. Data replication in the redundant cluster is handled at the application-layer, thereby ensuring that special-purpose hardware or software is not required to support the cluster
The redundancy option for the eG management console is a must-have for mission-critical environments that require 100% uptime of the management solution to enable rapid problem detection and immediate resolution.