Monitor servers, network, storage, cloud, and applications with a unified IT infrastructure monitoring solution powered by AIOps for faster troubleshooting.
Free TrialTrusted by leading companies


Modern IT infrastructures are heterogeneous and inter-dependent. They involve a number of different tiers that all perform specialized functions: Active Directory for user authentication, firewalls for security, load balancers for scale, virtualization for agility, storage for data retrieval, etc.
Often, each IT infrastructure tier has its own specialized monitoring tool. But administrators lack a single-pane-of-glass view into the IT infrastructure as a whole. The lack of unified IT monitoring solutions often leads to finger-pointing across tiers. Problems take longer to be resolved and troubleshooting is complicated and requires expertise.
eG Enterprise stands out as a leading IT infrastructure solution that simplifies managing your IT environment. By offering comprehensive IT infrastructure monitoring services, eG enables a unified approach to monitoring IT infrastructure and bridges the gap between different IT tiers.

eG Enterprise is an end-to-end IT performance management and monitoring suite for today's heterogeneous, hybrid and scale-out infrastructures. While specialized monitoring tools provide deep-dive visibility into each tier, eG Enterprise is a general practitioner for your IT infrastructure - i.e., it provides the unified console from where administrators can detect and resolve a majority of IT issues.
When it comes to monitoring IT performance, the IT infrastructure management tools you use must be comprehensive, intuitive, and versatile. As a robust infrastructure monitoring system, eG Enterprise equips IT administrators with the necessary tools to efficiently oversee all aspects of their IT landscape. This integrated approach speeds up problem resolution and enhances overall operational efficiency, making it one of the top IT infrastructure solutions for modern, dynamic IT environments.
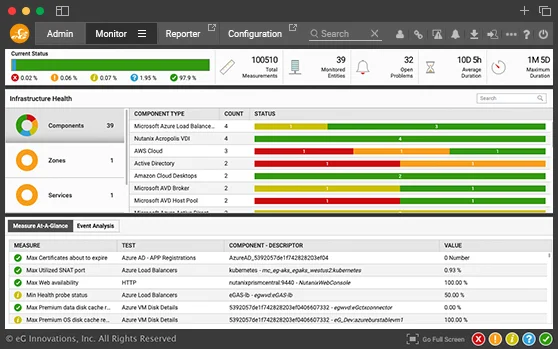
From a single pane of glass, IT administrators can monitor all aspects of their on-premises and cloud environments - across servers, applications, virtualization, storage, containers, and more.
Whether you're dealing with virtualized systems, cloud services, or traditional on-premises hardware, eG Enterprise's IT infrastructure monitoring capabilities ensure that every component is functioning optimally, keeping your IT backbone strong and reliable.

eG Enterprise offers unparalleled monitoring coverage for IT infrastructures, supporting 10+ operating systems, 10+ virtualization technologies, 20+ storage device types, and innumerable network devices. Add custom monitoring to eG Enterprise's extendable console.

eG Enterprise is an Enterprise-Class Solution, meaning our infrastructure monitoring tool is open, compatible, customizable, scalable, and secure. It's built to integrate seamlessly into existing and future architecture, safeguarding against internal and external threats.
Cater to different stakeholders in your organization with customizable dashboards and reports. Whether it's IT operations, helpdesk, domain experts, IT architects, or executives, eG Enterprise provides tailored views for each role, enhancing efficiency and focus.
")
eG fits perfectly into your existing setup. Whether it's incident management tools or existing reporting formats, eG Enterprise integrates without hassle, ensuring a smooth transition and operational continuity.

Designed with security at its core, eG Enterprise aligns with corporate security and firewall policies. It supports a push architecture and works seamlessly with secure proxy servers to ensure robust protection and easy deployment.

Experience the simplicity and flexibility in licensing. eG Enterprise avoids complicated models, offering straightforward options based on your specific monitoring needs, ensuring cost-effectiveness and ease of scalability.

Tailor eG Enterprise to your unique requirements. With open APIs, integrate custom monitoring capabilities seamlessly into your IT environment. It's designed for adaptability, allowing you to extend monitoring beyond out-of-the-box capabilities without complex programming.

Ideal for complex organizational structures. eG Enterprise offers personalized monitoring views for different departments or regions, ensuring efficiency and autonomy within a unified system.

No matter the diversity of your IT infrastructure, eG Enterprise supports a wide range of operating systems, virtualization platforms, cloud technologies, and storage technologies, making it a versatile choice for any large organization.

Designed to provide insights even with restricted access across different IT teams. eG Enterprise helps identify potential problem areas across domains, facilitating better communication and quicker resolution of any IT issue.

Built to handle the demands of large enterprises, eG Enterprise offers scalability and high availability options, ensuring consistent performance and reliability even in expansive and demanding IT environments.

eG Enterprise supports monitoring any type of server (including rack server, blade server, tower server, etc.) across a wide range of vendors such as HP, Dell, BMC, Cisco, and more.

eG Enterprise is a unified solution for monitoring all server and desktop operating systems:
eG Enterprise enables you to effectively monitor your multi-hypervisor virtual environment and identify critical bottlenecks that affect performance of business applications - whether in the hypervisor, host server, or guest virtual machine (VM). Using a patented "inside-outside" monitoring technology , eG Enterprise provides performance metrics from two vital perspectives:

Easily detect storage bottlenecks in external SAN and NAS arrays that affect application and server performance. eG Enterprise supports monitoring over 20 storage devices including EMC, NetApp, Dell, Hitachi, HPE, and more.

You can monitor the availability, fault and performance of any SNMP-enabled network device in your network including routers, firewall, switches, gateways, and load balancers from vendors such as Cisco, F5, HPE, Dell, Citrix, etc. Key network performance metrics monitored include:

Our network-aware application visibility provides correlated insight to help administrators easily identify if slow network connectivity is impacting application performance.

Today's business-critical IT infrastructures require solutions that provide ready answers to performance problems. IT infrastructure monitoring only provides part of the answers. Application performance monitoring provides insights if the issues are in the application code. Having different infrastructure and application monitoring solutions necessitates the need for manual oversight and analysis.
eG Enterprise is one of the industry's first converged application performance and infrastructure monitoring solutions.

Unified IT infrastructure monitoring provides a single, contextual view across servers, networks, storage, virtualization, cloud, and applications. By correlating performance across tiers, IT teams can detect issues faster, reduce troubleshooting time, and avoid finger‑pointing between teams.
Proactive insights help prevent outages, optimize capacity, and ensure consistent performance across on‑prem and cloud environments, all from one centralized console.
Unified IT infrastructure monitoring is designed to support modern, complex environments where applications and services span multiple platforms, locations, and technologies.



IT infrastructure monitoring is the continuous tracking of servers, networks, storage, cloud resources, and other components to ensure availability and performance.
Unified monitoring removes silos by providing a single, correlated view across all infrastructure layers but also their dependencies, enabling faster root cause analysis.
It typically includes monitoring of servers, networks, storage, virtualization, operating systems, databases, containers, and cloud services.
AIOps uses AI to automatically correlate data in real time, reduce alert noise, detect anomalies, and predict issues, helping teams resolve problems faster.
Learn more: AIOps Solutions and Strategies for IT Management | eG Innovations
Application Performance Monitoring (APM) focuses on application performance and user experience, while infrastructure monitoring tracks the health of underlying IT resources.
Some modern observability platforms such as eG Enterprise provide unified monitoring that consolidates and correlates data from application layers with that from infrastructure to avoid visibility gaps.
Yes, unified monitoring platforms, such as eG Enterprise, provide single pane visibility across cloud, network, servers, and related infrastructure components.
Monitoring detects issues early, speeds up troubleshooting, and enables proactive actions that prevent outages and performance degradation.
Effective monitoring needs automated root-cause analytics to alert on the root causes of downtime rather than to simply alert that a system is down. Learn more: Taking Server Monitoring to the Next Level | eG Innovations