

In this guide, I will cover the 5 best practices to follow for Kubernetes monitoring and alerting across Kubernetes clusters.
Kubernetes Monitoring and Alerting Best Practices
Briefly, these five best practices include the following groups:
What is Kubernetes and What is K8s?
 Kubernetes, also known as K8s, is a container-orchestration platform for automating deployment, scaling, and operations of applications running inside the containers across clusters of hosts. Google open-sourced the Kubernetes project in 2014. According to a recent CNCF survey, Kubernetes is the most popular container management tool among large enterprises, used by 83% of respondents.
Kubernetes, also known as K8s, is a container-orchestration platform for automating deployment, scaling, and operations of applications running inside the containers across clusters of hosts. Google open-sourced the Kubernetes project in 2014. According to a recent CNCF survey, Kubernetes is the most popular container management tool among large enterprises, used by 83% of respondents.
Related Information:
Why is Kubernetes Needed?
Containers are a good way to bundle and run applications. In a production environment, you need to manage the containers that run the applications and ensure that there is no downtime. For example, if a container goes down, another container needs to start to take over its functionality. This is where Kubernetes comes in.
Kubernetes provides a framework to run distributed systems resiliently. It takes care of scaling and failover for your application, provides deployment patterns, and more.
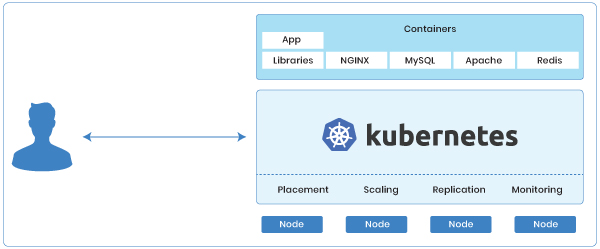
A few of the key capabilities of Kubernetes are:
- Service discovery and load balancing: Kubernetes can expose a DNS name and balance/distribute network traffic among multiple nodes to keep the deployment stable.
- Storage orchestration: With Kubernetes, you can automatically mount any storage system of your choice.
- Automated rollouts and rollbacks: You can describe the desired state for your containers using Kubernetes, and it can change the actual state to the desired state at a controlled rate.
- Automatic bin packing: You provide Kubernetes with a cluster of nodes that it can use to run containerized tasks. You tell Kubernetes how much CPU and memory (RAM) each container needs. Kubernetes can fit containers onto your nodes to make the best use of your resources.
- Self-healing: Kubernetes restarts containers that fail, replaces containers, kills containers that don’t respond to health checks, etc.
Why is Monitoring of Kubernetes Important?
In today’s technology landscape, Kubernetes plays a very vital role. Currently, Kubernetes is one of the most famous DevOps tools used by start-ups and large enterprises extensively. Big organizations have multiple Kubernetes clusters spread across multiple clouds or hybrid clouds with on-premises and with one or more cloud providers.
Although Kubernetes solves many existing IT problems, but it comes with its own set of complexities. And when you have multiple Kubernetes clusters to look after, the complexity increases. Hence, monitoring these Kubernetes clusters efficiently is very crucial. If you forget the monitoring angle and leave your Kubernetes environment unmonitored, you will know about the problems/issues only after they have occurred. It would be too late by then, and the damage would already have happened.
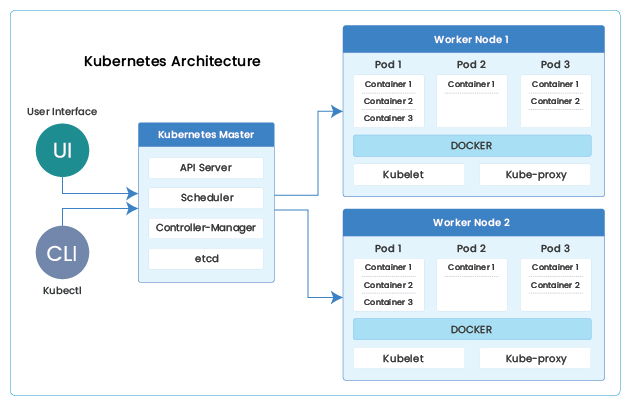
In this blog post, we will cover the best practices to follow for monitoring Kubernetes cluster(s).
Best Practices to Monitor Kubernetes Clusters
With Kubernetes, you can create levels of abstractions such as pods and services, which free you from worrying about where your applications are running, or if they have sufficient resources to run efficiently. But to ensure optimal performance, you must monitor your applications, the containers that run them, and even Kubernetes itself.
Five of the most important Kubernetes monitoring best practices include:
Use Kubernetes DaemonSets
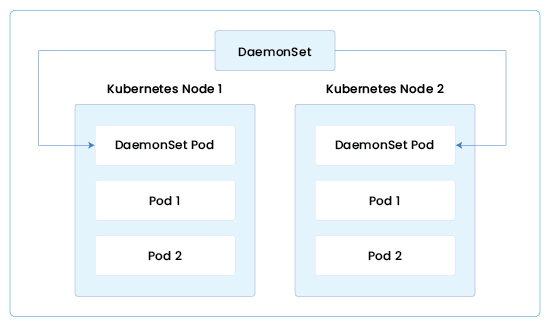
In Kubernetes, you should deploy a DaemonSet on each node that comes up in your Kubernetes environment. DaemonSet is a Kubernetes workload object, which is responsible for running a pod on every Kubernetes node. It is used to ensure that every new host that shows up is ready to go and provides metrics back to you.
It is one of the best practices to deploy your monitoring intelligence by using DaemonSets into your environment. Using DaemonSets help you collect metrics automatically, and then you get every information of your environment dynamically when they happen.
Use Labels and Tags
One of the important points while collecting all the metrics to monitor is using labels and tags. These are ways to interact with your pods and containers. Labelling cluster resources and objects help you monitor complex clusters with ease.
Tags and labels are essentially descriptors or ways to mark or identify different entities, such as the application or the container itself. Kubernetes has labels that can be associated with various components. For example, I can mark the label for a cloud provider. Then I can ask the monitoring system to show me everything labelled cloud provider with availability zone ‘west’. I can add tags to get into a much more granular level, which we like to call slicing and dicing. If you’re not providing descriptive labels and tags inside your environment, it will be challenging to monitor services and resources once your cluster becomes complex.
Use kube-state-metrics

There is this project that got started within the Kubernetes project itself that’s called kube-state-metrics. It provides information that helps the users of Kubernetes understand the state of the different pieces and parts of their Kubernetes cluster. Here are a few common questions, which kube-state-metrics answers:
- How many nodes are out of storage space?
- How many pods are yet to be scheduled?
- How many container restarts occurred in a pod?
- How many jobs are running/succeeded/failed?
- How many nodes are unavailable?
The metrics of these questions are very crucial when we talk about monitoring a Kubernetes cluster. kube-state-metrics are awesome and it’s something that you should look for as another dimension into monitoring Kubernetes. It is vital to know about your cluster’s state because when something doesn’t look right, you have an opportunity to solve that before it impacts anything in production.
Use Service Discovery
All the applications are scheduled dynamically by Kubernetes using the scheduling policy. You will not know which application is running where unless you use service discovery. Service discovery is used to connect to the services for collecting the application metrics. Additional to a monitoring system, you need to use service discovery to collect metrics of your application running on several moving containers. It will help you monitor all the dynamically deployed applications without any interruption.
Deploy Alerts on Monitoring System
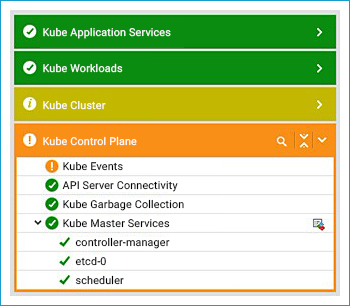
When you have your pretty monitoring dashboards ready with many metrics getting monitored in it, you obviously won’t be staring at the screen all day. This is where alerts come into the picture. Having an alerting system or alert manager with your monitoring system is a perfect combination. Alerts are used to automatically look for conditions you have configured and to notify/alert you if it finds any issue in the cluster.
These alerts can be focused on:
- Host resource metrics
- Container resource metrics
- Application metrics
- Service-oriented metrics
Service-oriented metrics are the closest to the user experience. When you monitor the service as a whole and how it behaves, that will give you an idea of how the users are experiencing your application. Alerts help you see the problems proactively, and obviously, it’s going to be helpful for the end customers, but it also helps your internal team. The developers also want to know if you see some problem with the service because they can iterate on the code potentially and fix that immediately. So, it’s good to use and set alerts in a Kubernetes cluster, and they scale with your environment.
eG Enterprise is an Observability solution for Modern IT. Monitor digital workspaces,
web applications, SaaS services, cloud and containers from a single pane of glass.
Conclusion
That was about the best practices to follow while monitoring Kubernetes clusters. If you are a system administrator or a DevOps engineer, go ahead and implement these practices for your organization’s Kubernetes cluster.
To monitor your Kubernetes cluster in production, check out the eG Enterprise Kubernetes monitoring solution, which provides in-depth visibility into the Kubernetes Cluster, monitors the Kubernetes control plane, tracks resource provisioning, monitors the performance and user experience of containerized applications, and much more.
eG Enterprise is an Observability solution for Modern IT. Monitor digital workspaces,
web applications, SaaS services, cloud and containers from a single pane of glass.



