The Kubernetes Architecture
At its base, Kubernetes brings together multiple physical or virtual servers into a cluster using a shared network to communicate between them. Though the cluster can contain any host that runs containerized applications, the most common or popular deployment of Kubernetes has it managing a cluster of Docker hosts. This cluster is the physical platform where all Kubernetes components, capabilities, and workloads are configured.
The machines in the cluster are each given a role within the Kubernetes ecosystem. One server (or a small group in highly available deployments) functions as the master server. This server acts as a gateway and brain for the cluster. It is the primary point of contact with the cluster and is responsible for most of the centralized logic Kubernetes provides.
The other servers in the cluster are designated as worker (or slave) nodes: servers responsible for accepting and running workloads using local and external resources. Worker nodes run applications and services in containers, and therefore require a container runtime (like Docker). The node receives work instructions from the master server and creates or destroys containers accordingly.
Together, the Kubernetes master and worker nodes form the Kubernetes control plane. To ensure the high availability of the containerized applications and services, the control plane responds to changes in the cluster and works to restore the cluster to its desired state.
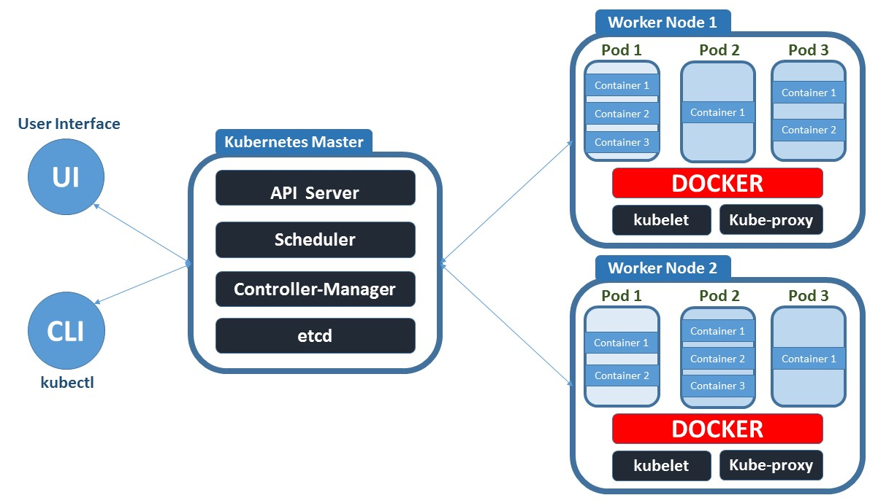
Figure 1 : Basic architecture of a Kubernetes Cluster
The cluster's desired state is typically defined by the user ( a developer/admin) who connects to the Kubernetes master server. To represent the state of a cluster, Kubernetes uses persistent entities called Objects. A Kubernetes object is a “record of intent”–once you create the object, the Kubernetes system will constantly work to ensure that object exists. By creating an object, you are effectively telling the Kubernetes system what you want your cluster’s workload to look like; this is your cluster’s desired state. Some of the most commonly used Kubernetes objects include:
- Pod: A Pod represents a unit of deployment: a single instance of an application in Kubernetes, which might consist of either a single Docker container or a small number of containers that are tightly coupled and that share resources. Other than container(s), a Pod encapsulates a unique network IP and options that govern how the container(s) should run.
- Service: A Service is an abstraction which defines a logical set of Pods and a policy by which to access them (sometimes this pattern is called a micro-service).
- Volume: At its core, a volume is just a directory, possibly with some data in it, which is accessible to the containers in a Pod.
- Namespace: Kubernetes supports multiple virtual clusters called Namespaces, which are backed by the same physical cluster. Namespaces are a way to divide cluster resources between multiple users (via resource quota).
- ReplicaSet: A ReplicaSet’s purpose is to maintain a stable set of replica Pods running at any given time. As such, it is often used to guarantee the availability of a specified number of identical Pods.
- Deployment: A Deployment provides declarative updates for Pods and ReplicaSets. You describe a desired state in a Deployment. You can define Deployments to create new ReplicaSets, or to remove existing Deployments and adopt all their resources with new Deployments.
- DaemonSet: A DaemonSet ensures that all (or some) Nodes run a copy of a Pod - eg., running a cluster storage daemon, such as glusterd, ceph, on each node.
Every Kubernetes object includes two nested object fields that govern the object’s configuration: the object spec and the object status. When a user connects to the master server, he/she must provide a spec describing the desired state for the object–the characteristics that the user wants the object to have. For instance, a Kubernetes Deployment is an object that can represent an application running on the cluster. When the user creates the Deployment, he/she might set the Deployment spec to specify that they want three replicas of the application to be running.
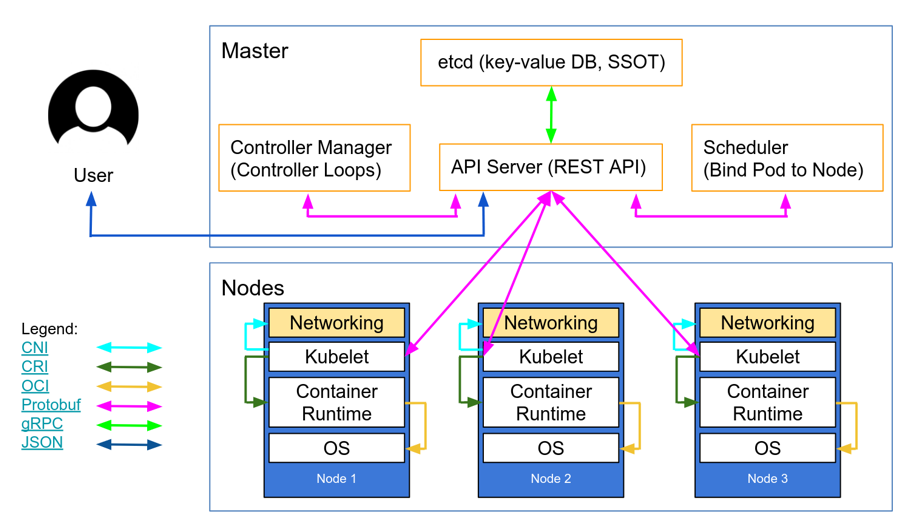
Figure 2 : How the Kubernetes Cluster works
The master server exposes a Kubernetes API (the kube-apiserver process), which receives the object spec from the user. The API then runs the spec by the scheduler (the kube-scheduler process). The scheduler selects the worker (or slave) node to which the new objects should be assigned. Factors taken into account for scheduling decisions include individual and collective resource requirements, hardware/software/policy constraints, affinity and anti-affinity specifications, data locality, inter-workload interference and deadlines. Alongside, the master sever also stores the configuration and status data of objects created, in a consistent, highly-available key-value store called etcd.
Once the scheduler assigns a worker (or slave) node, the controller manager (the kube-controller-manager process) on the master node then sends the object spec to that node (via the Kubernetes API), so it can create the desired object.
Upon receipt of the object spec, the kubelet on that node ensures objects are created accordingly. The kubelet is the node-agent that resides on each worker node. The kubelet is also responsible for registering a node with a Kubernetes cluster, and sending events, pod status, and resource utilization reports to the master server.
At frequent intervals, the kubelet, via the API, updates the etcd on the master with the Object status of objects. This is the actual state of the objects. The watch functionality of etcd monitors changes to the Object spec (i.e., desired state) and the Object status (i.e., actual state). If the Object spec and Object status do not match, then the control loops run by the controller manager respond to these discrepancies and work to make the actual state of all the objects in the system match the desired state that the user provided. For example, if the kubelet reports that a Pod in a ReplicaSet is down, then the etcd's watch functionality figures out that the object spec is not in sync with the object status. To manage the state of objects, the controller manager, through control loops, sends instructions (via API) to the kubelet to create another Pod or restart the Pod that is down, and thus restores the ReplicaSet object to its desired state.