What is MongoDB Cluster?
In contrast to a single-server MongoDB database, a MongoDB cluster allows a MongoDB database to either horizontally scale across many servers with sharding, or to replicate data ensuring high availability with MongoDB replica sets, therefore, enhancing the overall performance and reliability of MongoDB clusters.
In the context of MongoDB, “cluster” is the word usually used for either a replica set or a sharded cluster. A replica set is the replication of a group of MongoDB servers that hold copies of the same data. This is a fundamental property for production deployments as it ensures high availability and provides redundancy, which are crucial features to have in place in case of failovers and planned maintenance periods.
A sharded cluster in MongoDB is a collection of data distributed across many shards (servers) in order to achieve horizontal scalability and better performance in read and write operations. Sharding is very useful for collections that have a lot of data and high query rates. The Shard cluster architecture consists of three components (see Figure 1)
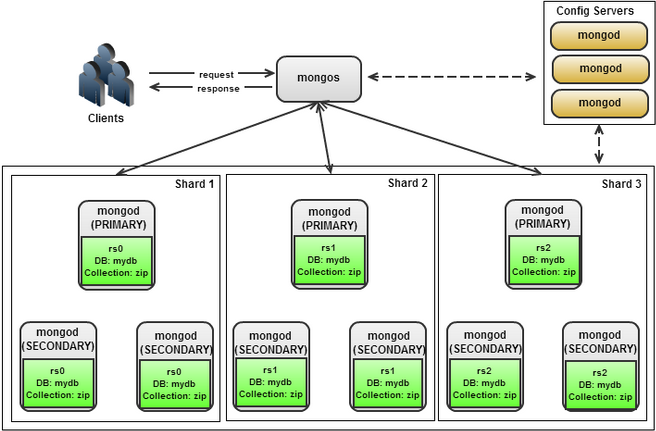
Figure 1 : Sharded Cluster Architecture
The Shard cluster architecture consists of three components.
-
Shard server: The shard is a database server that consists of different replica sets that each hold a portion of your data. Each replica set or shard is responsible for some indexed value in your database.
-
Query router (mongos): Mongos is a process running on the client application communicating with MongoDB. Because the data is distributed between different shards, the query must be routed to the shard that holds the requested data. It is standard practice to have different query routers for each application server.
-
Config server: The configuration server stores metadata for the shards. Mongos communicates with the config server to figure out which replica sets to query for data. Typically, the configuration servers must consist of at least three servers. They do not provide failover capability. If one configuration server fails, the cluster becomes unavailable.
A MongoDB replica set ensures replication is enforced by providing data redundancy and high availability over more than one MongoDB server. If a MongoDB deployment lacked a replica set, that means all data would be present in exactly one server. In case that main server fails, then all data would be lost - but not when a replica set is enabled. In addition to fault tolerance, replica sets can also provide extra read operations capacity for the MongoDB cluster, directing clients to the additional servers, subsequently reducing the overall load of the cluster. Replica sets can also be beneficial for distributed applications due to the data locality they offer, so that faster and parallel read operations happen to the replica sets instead of having to go through one main server.
A MongoDB cluster needs to have a primary node and a set of secondary nodes in order to be considered a replica set. At most, one primary node must exist, and its role is to receive all write operations. All changes on the primary node’s data sets are recorded in a special capped collection called the operation log (oplog). The role of the secondary nodes is to then replicate the primary node’s operation log and make sure that the data sets reflect exactly the primary’s data sets. This functionality is illustrated in the following diagram:
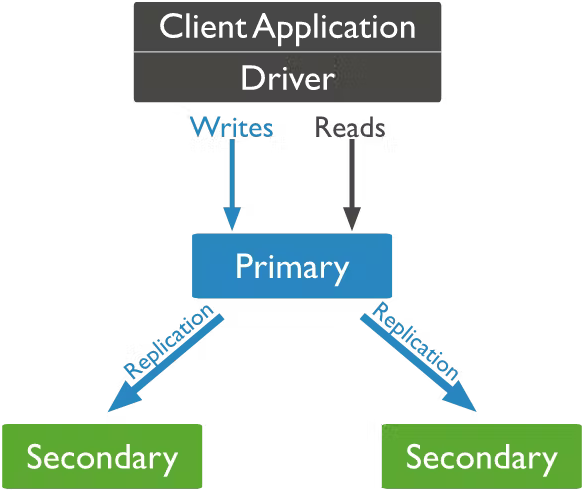
Figure 2 : Working of Replicaset cluster
The replication from the primary node’s oplog to the secondaries happens asynchronously, which allows the replica set to continue to function despite potential failure of one or more of its members. If the current primary node suddenly becomes unavailable, an election will take place to determine the new primary node. In the scenario of having two secondary nodes, one of the secondary nodes will become the primary node. If for any reason only one secondary node exists, a special instance called arbiter can be added to a replica set which can only participate in replica set elections but does not replicate the oplog from the primary. This means it can’t provide data redundancy and it will always be an arbiter, i.e., it can’t become a primary or a secondary node, whereas a primary can become a secondary node and vice versa.
The failure of a primary node is not the only reason a replica set election can occur. Replica set elections can happen for other reasons in response to a variety of events, such as when a new node is added in the replica set, on the initiation of a replica set, during maintenance of the replica set, or if any secondary node loses connectivity to the primary node for a period more than the configured timeout period (‘10sec’ by default).