AWS Simple Storage Service(S3) - Storage Statistics Test
Amazon Simple Storage Service is storage for the Internet. Amazon S3 has a simple web services interface that you can use to store and retrieve any amount of data, at any time, from anywhere on the web.
To upload data to the cloud, you first create a bucket in one of the AWS Regions. A bucket is a container for data stored in Amazon S3. Once a bucket is created, you can then upload any number of objects to the bucket. Objects are the fundamental entities stored in Amazon S3, and consist of object data and metadata. Every object is contained in a bucket. For example, if the object named photos/puppy.jpg is stored in the johnsmith bucket, then it is addressable using the URL http://johnsmith.s3.amazonaws.com/photos/puppy.jpg
Each object in Amazon S3 has a storage class associated with it. Amazon S3 offers the following storage classes for the objects that you store. You choose one depending on your use case scenario and performance access requirements.
- STANDARD – This storage class is ideal for performance-sensitive use cases and frequently accessed data. STANDARD is the default storage class; if you do not specify storage class at the time that you upload an object, Amazon S3 assumes the STANDARD storage class.
- STANDARD_IA – This storage class (IA, for infrequent access) is optimized for long-lived and less frequently accessed data. For example - backups and older data where frequency of access has diminished, but the use case still demands high performance. The STANDARD_IA objects are available for real-time access.
- GLACIER – The GLACIER storage class is suitable for archiving data where data access is infrequent. Archived objects are not available for real-time access. You must first restore the objects before you can access them. For more information, see Restoring Archived Objects.
- REDUCED_REDUNDANCY – The Reduced Redundancy Storage (RRS) storage class is designed for noncritical, reproducible data stored at lower levels of redundancy than the STANDARD storage class.
The STANDARD_IA storage class is suitable for larger objects greater than 128 Kilobytes that you want to keep for at least 30 days. For example, bucket lifecycle configuration has minimum object size limit for Amazon S3 to transition objects. For more information, see Supported Transitions and Related Constraints.
You cannot specify GLACIER as the storage class at the time that you create an object. You create GLACIER objects by first uploading objects using STANDARD, RRS, or STANDARD_IA as the storage class. Then, you transition these objects to the GLACIER storage class using lifecycle management.
To know how many buckets have been created in each region and how many objects are stored in each storage class by every bucket, use the AWS Simple Storage Service(S3) - Storage Statistics test.
This test automatically discovers the buckets that have been created in every region and reports the total count and size of objects in each bucket. You can then use the detailed diagnosis of this test to know in which storage classes each bucket is currently storing objects, and the total size of objects in each class.
Target of the test: Amazon Cloud
Agent deploying the test : A remote agent
Outputs of the test : One set of results for each bucket in each AWS region
First-level descriptor: AWS Region
Second-level descriptor: Bucket name
| Parameter | Description |
|---|---|
|
Test Period |
How often should the test be executed. |
|
Host |
The host for which the test is to be configured. |
|
Access Type |
eG Enterprise monitors the AWS cloud using AWS API. By default, the eG agent accesses the AWS API using a valid AWS account ID, which is assigned a special role that is specifically created for monitoring purposes. Accordingly, the Access Type parameter is set to Role by default. Furthermore, to enable the eG agent to use this default access approach, you will have to configure the eG tests with a valid AWS Account ID to Monitor and the special AWS Role Name you created for monitoring purposes.
Some AWS cloud environments however, may not support the role-based approach Note that the Secret option may not be ideal when monitoring high-security cloud environments. This is because, such environments may issue a security mandate, which would require administrators to change the Access Key and Secret Key, often. Because of the dynamicity of the key-based approach, Amazon recommends the Role-based approach for accessing the AWS API. |
|
AWS Account ID to Monitor |
This parameter appears only when the Access Type parameter is set to Role. Specify the AWS Account ID that the eG agent should use for connecting and making requests to the AWS API. To determine your AWS Account ID, follow the steps below:
|
|
AWS Role Name |
This parameter appears when the Access Type parameter is set to Role. Specify the name of the role that you have specifically created on the AWS cloud for monitoring purposes. The eG agent uses this role and the configured Account ID to connect to the AWS Cloud and pull the required metrics. To know how to create such a role, refer to Creating a New Role. |
|
AWS Access Key, AWS Secret Key, Confirm AWS Access Key, Confirm AWS Secret Key |
These parameters appear only when the Access Type parameter is set to Secret.To monitor an Amazon cloud instance using the Secret approach, the eG agent has to be configured with the access key and secret key of a user with a valid AWS account. For this purpose, we recommend that you create a special user on the AWS cloud, obtain the access and secret keys of this user, and configure this test with these keys. The procedure for this has been detailed in the Obtaining an Access key and Secret key topic. Make sure you reconfirm the access and secret keys you provide here by retyping it in the corresponding Confirm text boxes. |
|
Proxy Host and Proxy Port |
In some environments, all communication with the AWS cloud and its regions could be routed through a proxy server. In such environments, you should make sure that the eG agent connects to the cloud via the proxy server and collects metrics. To enable metrics collection via a proxy, specify the IP address of the proxy server and the port at which the server listens against the Proxy Host and Proxy Port parameters. By default, these parameters are set to none , indicating that the eG agent is not configured to communicate via a proxy, by default. |
|
Proxy User Name, Proxy Password, and Confirm Password |
If the proxy server requires authentication, then, specify a valid proxy user name and password in the Proxy User Name and Proxy Password parameters, respectively. Then, confirm the password by retyping it in the Confirm Password text box. By default, these parameters are set to none, indicating that the proxy sever does not require authentication by default. |
|
Proxy Domain and Proxy Workstation |
If a Windows NTLM proxy is to be configured for use, then additionally, you will have to configure the Windows domain name and the Windows workstation name required for the same against the Proxy Domain and Proxy Workstation parameters. If the environment does not support a Windows NTLM proxy, set these parameters to none. |
|
Exclude Region |
Here, you can provide a comma-separated list of region names or patterns of region names that you do not want to monitor. For instance, to exclude regions with names that contain 'east' and 'west' from monitoring, your specification should be: *east*,*west* |
|
Default Connection Region |
By default, this test connects to the endpoint URL of the us-east-1 region to collect the required metrics. If the default us-east-1 region is not enabled in the target environment, then, for this test to collect the required metrics, specify the region that is enabled in the target environment. |
|
Detailed Diagnosis |
To make diagnosis more efficient and accurate, the eG Enterprise embeds an optional detailed diagnostic capability. With this capability, the eG agents can be configured to run detailed, more elaborate tests as and when specific problems are detected. To enable the detailed diagnosis capability of this test for a particular server, choose the On option. To disable the capability, click on the Off option. The option to selectively enable/disable the detailed diagnosis capability will be available only if the following conditions are fulfilled:
|
|
Measurement |
Description |
Measurement Unit |
Interpretation |
|||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
Total objects |
Indicates the total number of objects stored in this bucket for all storage classes except for the GLACIER storage class.
|
Number |
|
|||||||||
|
Bucket size |
Indicates the amount of data stored in a bucket in the Standard storage class, Standard - Infrequent Access (Standard_IA) storage class, and/or the Reduced Redundancy Storage (RRS) class.
|
GB |
Use the detailed diagnosis of this measure to know the storage classes in which the bucket stores object, and the total size of objects in each class. |
|||||||||
|
Access type |
Indicates whether this bucket has private or public access. |
|
The values that this measure reports and their corresponding numeric values are detailed in the table below:
Note: By default, this measure reports the Measure Values listed in the table above to indicate the access type of a bucket. In the graph of this measure however, the same is indicated using the numeric equivalents. |
Use the detailed diagnosis of the Bucket size measure to know which storage classes S3 stores the bucket's objects in and the total size of these objects per class.
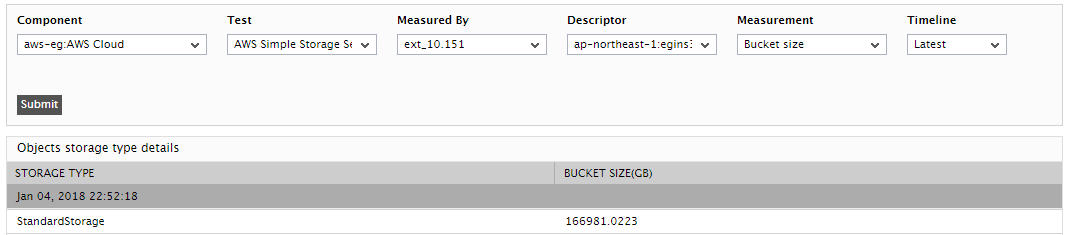
Figure 2 : The detailed diagnosis of the Bucket size measure