Introduction
SAP HANA is a flexible, data-source-agnostic appliance that allows customers to analyze large volumes of SAP ERP data in real-time, avoiding the need to materialize transformations. SAP HANA is a hardware and software combination that integrates a number of SAP components including the SAP In-memory database, Sybase Replication technology and SAP LT (Landscape Transformation) Replicator. SAP HANA is delivered as an optimized appliance in conjunction with leading SAP hardware partners.
Figure 3 depicts the architecture of SAP HANA.
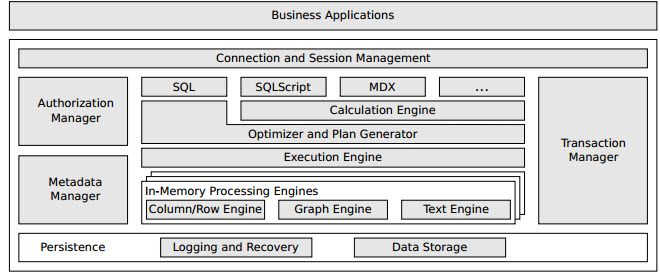
Figure 3 : The architecture of SAP HANA
The heart of the SAP HANA DB consists of a set of in-memory processing engines. Relational data resides in tables in column or row layout in the combined column and row engine, and can be converted from one layout to the other to allow query expressions with tables in both layouts. Graph data and text data reside in the graph engine and the text engine respectively; more engines are possible due to the extensible architecture. All engines keep all data in main memory as long as there is enough space available. As one of the main distinctive features, all data structures are optimized for cache-efficiency instead of being optimized for organization in traditional disk blocks. Furthermore, the engines compress the data using a variety of compression schemes. When the limit of available main memory is reached, entire data objects, e.g., tables or partitions, are unloaded from main memory under control of application semantic and reloaded into main memory when it is required again. From an application perspective, the SAP HANA DB provides multiple interfaces, such as standard SQL for generic data management functionality or more specialized languages as SQLScript and MDX. SQL queries are translated into an execution plan by the plan generator, which is then optimized and executed by the execution engine. Queries from other interfaces are eventually transformed into the same type of execution plan and executed in the same engine, but are first described by a more expressive abstract data flow model in the calculation engine. Irrespective of the external interface, the execution engine can use all processing engines and handles the distribution of the execution over several nodes. As in traditional database systems, the SAP HANA DB has components to manage the execution of queries. The session manager controls the individual connections between the database layer and the application layer, while the authorization manager governs the user’s permissions. The transaction manager implements snapshot isolation or weaker isolation levels – even in a distributed environment. The metadata manager is a repository of data describing the tables and other data structures, and, like the transaction manager, consists of a local and a global part in case of distribution.
While virtually all data is kept in main memory by the processing engines for performance reasons, data has also to be stored by the persistence layer for backup and recovery in case of a system restart after an explicit shutdown or a failure. Updates are logged as required for recovery to the last committed state of the database and entire data objects are persisted into the data storage regularly.
Owing to its fail-proof architecture, the SAP HANA database server is widely used in many mission-critical IT infrastructures delivering essential services to end-users. In such environments, even a second’s non-availability of the database server will not be tolerated, as it may significantly delay service delivery and affect user satisfaction with the service. To ensure high uptime of such services, the availability and overall performance of the SAP HANA database server should be continuously monitored and errors brought to the immediate attention of the administrators. This is what exactly eG Enterprise offers.