
System Details Test
This operating system-specific test relies on native measurement capabilities of the operating system to collect various metrics pertaining to the CPU and memory usage of a host system. The details of this test are as follows:
Target of the test : Any host system
Agent deploying the test : An internal agent
Outputs of the test : One set of results for each host monitored
| Parameter | Description |
|---|---|
|
Test Period |
How often should the test be executed |
|
Host |
The host for which the test is to be configured. |
|
Duration |
This parameter is of significance only while monitoring Unix hosts, and indicates how frequently within the specified test period, the agent should poll the host for CPU usage statistics. |
|
Summary |
This attribute is applicable to multi-processor systems only. If the Yes option is selected, then the eG agent will report not only the CPU and memory utilization of each of the processors, but it will also report the summary (i.e., average) of the CPU and memory utilizations of the different processors. If the No option is selected, then the eG agent will report only the CPU usage of the individual processors. |
|
Useiostat |
This parameter is of significance to Solaris platforms only. By default, the useiostat flag is set to No. This indicates that, by default, SystemTest reports the CPU utilization of every processor on the system being monitored, and also provides the average CPU utilization across the processors. However, if you want SystemTest to report only the average CPU utilization across processors and across user sessions, then set the useiostat flag to Yes. In such a case, the processor-wise breakup of CPU utilization will not be available. |
|
UsePS |
This flag is applicable only for AIX LPARs. By default, this flag is set to No |
|
Show Steal Time |
By default, this flag is set to No, indicating that this test does not report the Steal time measure by default. However, when monitoring a Linux/Windows VM that is provisioned via a VMware vSphere ESX server, you can set this flag to Yes. This is because, the Steal time measure is reported only for such VMs. |
|
Useglance |
This flag applies only to HP-UX systems. HP GlancePlus/UX is Hewlett-Packards’s online performance monitoring and diagnostic utility for HP-UX based computers. There are two user interfaces of GlancePlus/UX -- Glance is character-based, and gpm is motif-based. Each contains graphical and tabular displays that depict how primary system resources are being utilized. In environments where Glance is run, the eG agent can be configured to integrate with Glance to pull out detailed metrics pertaining to the CPU usage of the HP-UX systems that are being monitored. By default, this integration is disabled. This is why the Useglance flag is set to No by default. You can enable the integration by setting the flag to Yes. If this is done, then the test polls the Glance interface of HP GlancePlus/UX utility to report the detailed diagnosis information. |
|
Exclude |
Specify a comma-separated list of processor names / processor name patterns that you want to exclude from monitoring. For example:*kernel*, *cpu*. |
|
Include wait |
This flag is applicable to Unix hosts alone. On Unix hosts, CPU time is also consumed when I/O waits occur on the host. By default, on Unix hosts, this test does not consider the CPU utilized by I/O waits while calculating the value of the CPU utilization measure. Accordingly, the include wait flag is set to No by default. To make sure that the CPU utilized by I/O waits is also included in CPU usage computations on Unix hosts, set this flag to Yes. |
|
High Security |
This flag is applicable only when the target Linux host is monitored in the agentless manner. In highly secure environments, eG Enterprise could not perform agentless monitoring on a Linux host using SSH. To enable monitoring of the Linux hosts in such environments, set the HIGH SECURITY flag to Yes. It indicates that eG Enterprise will connect to the target Linux host in a more secure way and collect performance metrics. By default, this flag is set to No. |
|
DD Frequency |
Refers to the frequency with which detailed diagnosis measures are to be generated for this test. The default is 1:1. This indicates that, by default, detailed measures will be generated every time this test runs, and also every time the test detects a problem. You can modify this frequency, if you so desire. Also, if you intend to disable the detailed diagnosis capability for this test, you can do so by specifying none against DD frequency. |
|
Detailed Diagnosis |
To make diagnosis more efficient and accurate, the eG Enterprise embeds an optional detailed diagnostic capability. With this capability, the eG agents can be configured to run detailed, more elaborate tests as and when specific problems are detected. To enable the detailed diagnosis capability of this test for a particular server, choose the On option. To disable the capability, click on the Off option. The option to selectively enable/disable the detailed diagnosis capability will be available only if the following conditions are fulfilled:
|
|
Measurement |
Description |
Measurement Unit |
Interpretation |
|---|---|---|---|
|
CPU utilization: |
This measurement indicates the percentage of utilization of the CPU time of the host system. |
Percent |
A high value could signify a CPU bottleneck. The CPU utilization may be high because a few processes are consuming a lot of CPU, or because there are too many processes contending for a limited resource. Check the currently running processes to see the exact cause of the problem. |
|
System CPU utilization: |
Indicates the percentage of CPU time spent for system-level processing. |
Percent |
An unusually high value indicates a problem and may be due to too many system-level tasks executing simultaneously. |
|
Run queue length: |
Indicates the instantaneous length of the queue in which threads are waiting for the processor cycle. This length does not include the threads that are currently being executed. |
Number |
A value consistently greater than 2 indicates that many processes could be simultaneously contending for the processor. |
|
Blocked processes: |
Indicates the number of processes blocked for I/O, paging, etc. |
Number |
A high value could indicate an I/O problem on the host (e.g., a slow disk). |
|
Swap memory: |
On Windows systems, this measurement denotes the committed amount of virtual memory. This corresponds to the space reserved for virtual memory on disk paging file(s). On Solaris systems, this metric corresponds to the swap space currently available. On HPUX and AIX systems, this metric corresponds to the amount of active virtual memory (it is assumed that one virtual page corresponds to 4 KB of memory in this computation). |
MB |
An unusually high value for the swap usage can indicate a memory bottleneck. Check the memory utilization of individual processes to figure out the process(es) that has (have) maximum memory consumption and look to tune their memory usages and allocations accordingly. |
|
Free memory: |
Indicates the amount of memory (including standby and free memory) that is immediately available for use by processes, drivers or Operating System. |
MB |
This measure typically indicates the amount of memory available for use by applications running on the target host. On Unix operating systems (AIX and Linux), the operating system tends to use parts of the available memory for caching files, objects, etc. When applications require additional memory, this is released from the operating system cache. Hence, to understand the true free memory that is available to applications, the eG agent reports the sum of the free physical memory and the operating system cache memory size as the value of the Free memory measure while monitoirng AIX and Linux operating systems. |
|
Steal Time |
Indicates the percentage of time a virtual processor waits for a real CPU while the hypervisor is servicing another virtual processor. |
Percent |
This measure is applicable only for the Linux / Windows VMs that are provisioned via a VMware vSphere ESX. A low value is desired for this measure. A high value for this measure indicates that a particular virtual processor is waiting longer for real CPU resources. If this condition is left unattended, it can stall the tasks performed by the virtual processor and cause the overall performance of the virtual processor to deteriorate significantly and badly impact user-experience with the target server. The impact of stolen CPU always manifests in slowness but can have more profound effects on your infrastructure. Here are some examples:
To avoid such eventualities, administrators should either immediately terminate the virtual machine and launch a replacement or upgrade the VM to have more CPU. |
Note:
For multi-processor systems, where the CPU statistics are reported for each processor on the system, the statistics that are system-specific (e.g., run queue length, free memory, etc.) are only reported for the "Summary" descriptor of this test.
The detailed diagnosis capability of the System CPU utilization and CPU utilization measures, if enabled, provides a listing of the top 10 CPU-consuming processes (see Figure 1). In the event of a Cpu bottleneck, this information will enable users to identify the processes consuming a high percentage of CPU time. The users may then decide to stop such processes, so as to release the CPU resource for more important processing purposes.
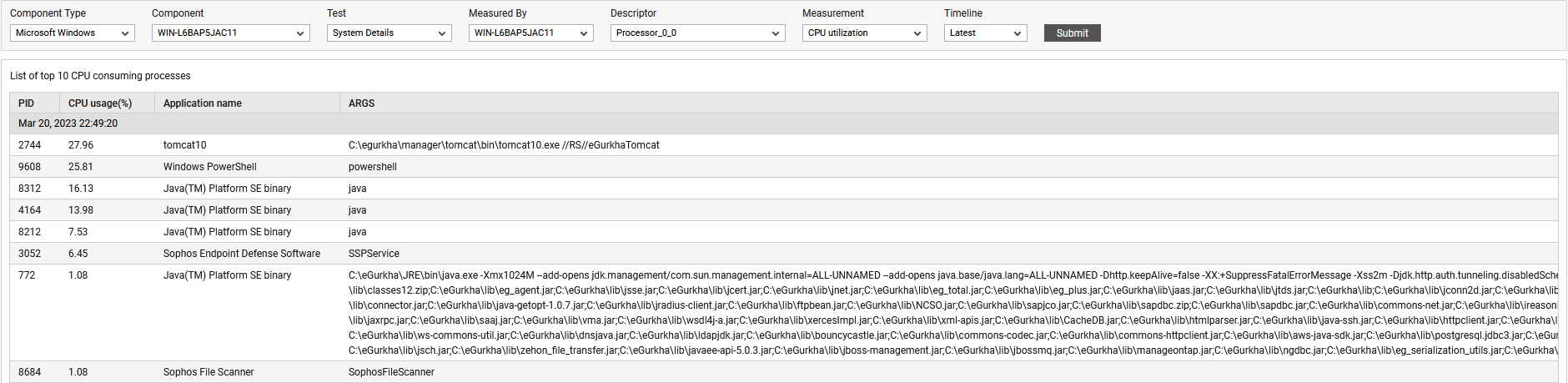
Figure 1 : Figure 2.3: The top CPU consuming processes
Note:
While instantaneous spikes in CPU utilization are captured by the eG agents and displayed in the Measures page, the detailed diagnosis will not capture/display such instantaneous spikes. Instead, detailed diagnosis will display only a consistent increase in CPU utilization observed over a period of time.
