The Network Dashboard
The Network Dashboard provides you with an overview of the network and TCP traffic to and from a VM, and in the process reveals the following:
- Is network load balanced across all the interfaces supported by the VM, or is any interface currently experiencing excessive incoming/outgoing traffic?
- Which network interface is utilizing the maximum bandwidth and why?
- Are too many TCP connections currently alive on the VM?
- Were any connections dropped?
- Did any TCP connection attempt fail?
- Were there too many TCP retransmits?
Like the System dashboard, the contents of the Network dashboard too are primarily governed by the choice of Subsystem. By default, Overview is chosen as the network Subsystem. If need be, you can choose the Network or Tcp Subsystems instead.
The sections that will follow will focus on each of these Subsystems.
-
Overview
In the Overview mode, the dashboard provides an all-round view of both the network and TCP health of the VM, enabling you to ascertain in a single glance:
- The current status of the network and TCP connections to the VM;
- Issues (if any) currently affecting network/TCP performance;
-
How network traffic, bandwidth usage, and overall TCP activity on the VM varied over the last 1 hour (by default), and what were the peak points/bottleneck areas
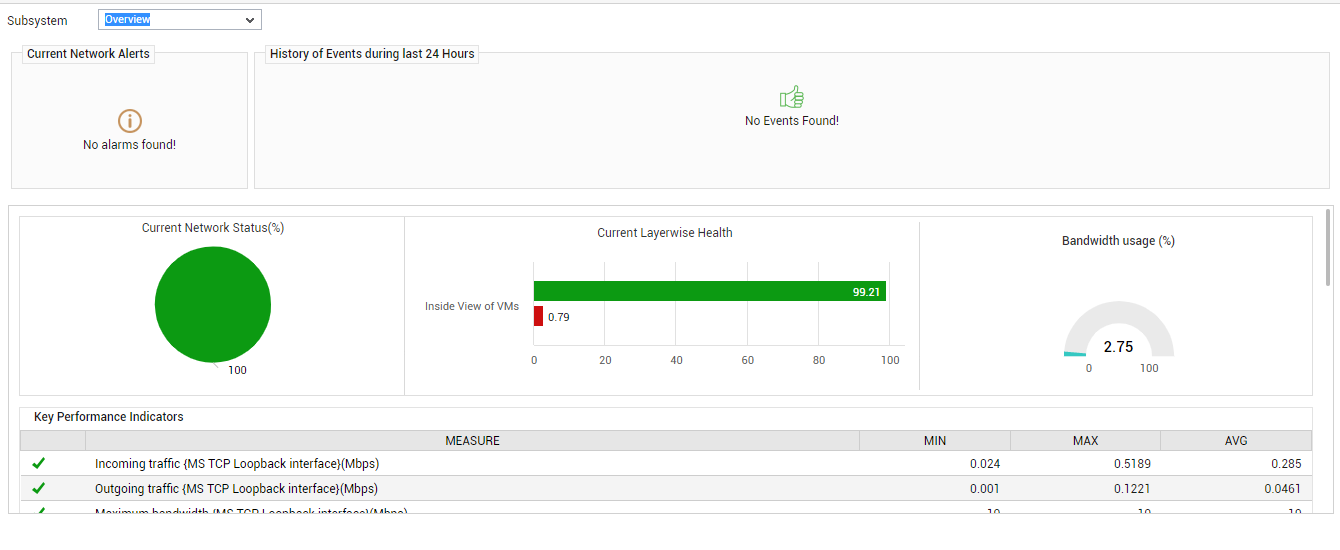
Figure 1 : The Network Overview Dashboard
The contents of the Overview dashboard have been discussed hereunder:
- The Current Network Alerts sections reveals the number and type of network-related issues currently affecting VM health.
-
You can receive a fair idea of how problem-prone the VM has been in the past, by taking a look at the History of Events section (not shown in ). For every alarm priority, this section indicates the number of network/TCP-related problems that were experienced by the VM during the last 24 hours. Alongside this depiction, you will also find a table that reveals the average, maximum, and minimum duration for which a problem remained unresolved during the last 24 hours; from this information, you can infer how long your administrative staff took to turnaround, when faced with issues - this enables you to judge the efficiency of your staff better. For more details pertaining to the historical issues, click on a bar in the History of Events bar chart. The page that then appears provides the complete event history.
- Below the History of Events section is the Current Network Status pie chart. This pie chart is a good indicator of the current network health of the VM, as it reveals the percentage of network-related measures that are currently in an abnormal state.
-
Similarly, you have the Current Layerwise Health bar graph that indicates how healthy the network-related measures reported by the Inside View of VMslayer of the VM currently are. If this bar chart and the Current Network Status pie chart reveal poor network health, then, you might want to know what is causing this - the Bandwidth usage dial chart and the Key Performance Indicators section reveal just that! By displaying the current bandwidth usage of the VM, the dial chart alerts you to excessive bandwidth consumption by that VM. By displaying the minimum, maximum, and average values of certain critical factors that influence network performance, the Key Performance Indicators section enables you to determine whether any of these factors could have contributed to the problem at hand. To know how any of these factors are currently performing, click on that particular key performance indicator listed in this section. Figure 2 will then appear.
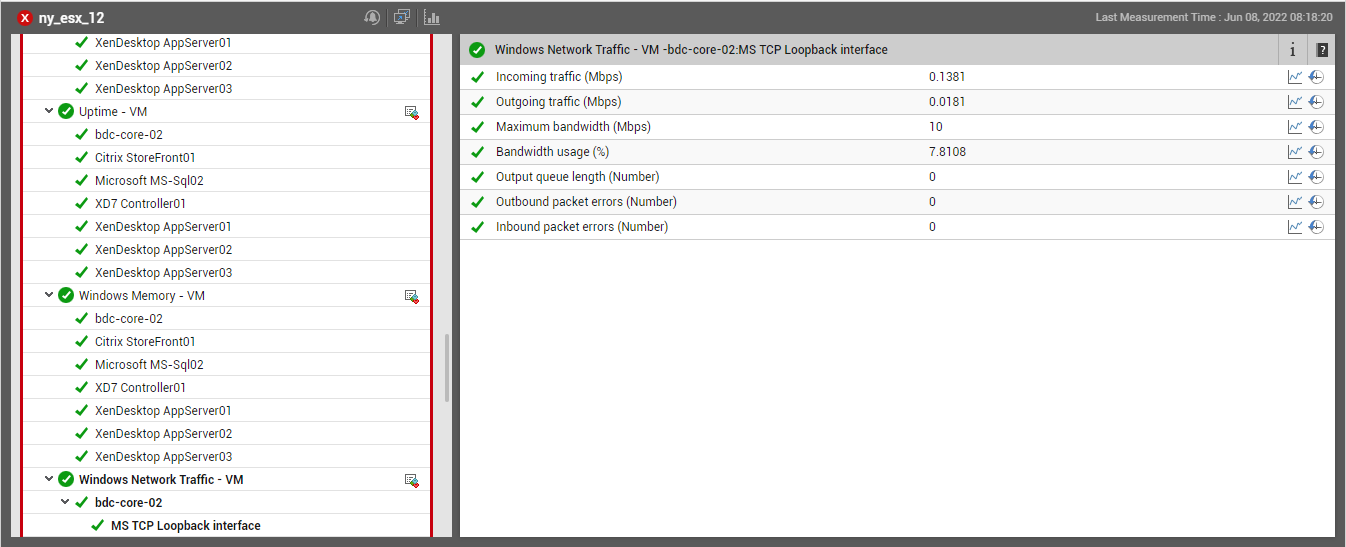
-
For historically analyzing network/TCP health and for detecting exactly when and why bottlenecks surfaced, use the measure graphs provided by the dashboard (see Figure 3).
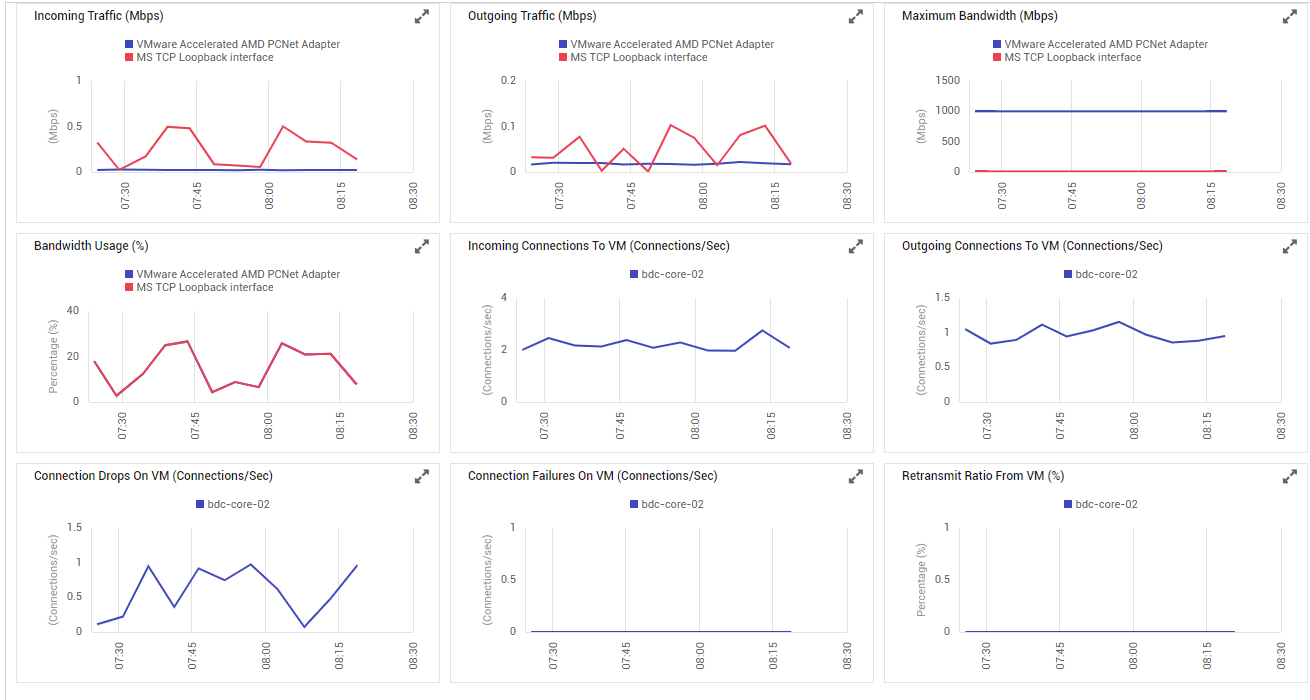
Figure 3 : Measure graphs on network usage
These graphs, by default, track the variations in network performance over the last 1 hour. In the event of a network issue with the VM, you can use these graphs to determine whether the issue occurred suddenly or is only the climax of a consistent deterioration in network performance.
-
Click on a
 icon in a graph to enlarge it. In the magnified mode, you can even change the Timeline of the graph, so as to obtain deeper insights into the past performance of the VM. In the case of graphs that plot values for multiple descriptors, you can pick a top-n or last-n option from the Show list and thus focus on the best/worst performers alone.
icon in a graph to enlarge it. In the magnified mode, you can even change the Timeline of the graph, so as to obtain deeper insights into the past performance of the VM. In the case of graphs that plot values for multiple descriptors, you can pick a top-n or last-n option from the Show list and thus focus on the best/worst performers alone. 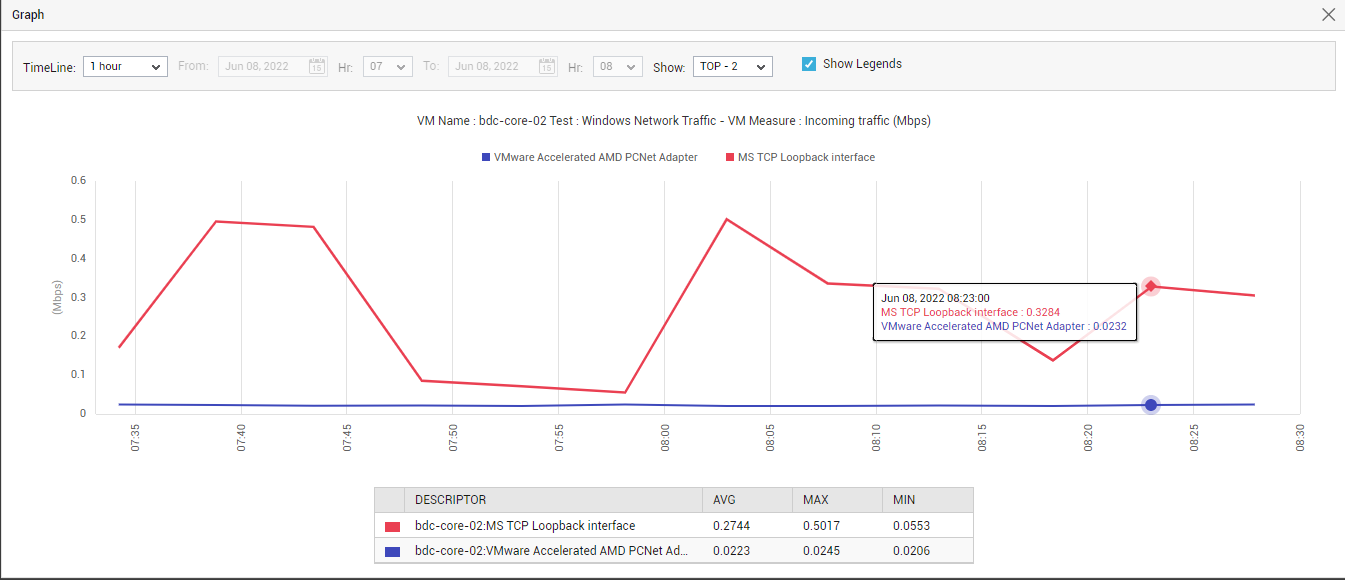
Figure 4 : An enlarged network traffic graph
-
Network
To focus on network performance, select Network as the Subsystem. Figure 5 will then appear. The dial chart in Figure 5 will indicate if the VM is experiencing any bandwidth contention currently. You can also take help from the time-of-day graphs displayed in this dashboard to perform the following with ease:
- Track the variations in network traffic to and from the VM over the default period of 1 hour;
- Isolate network delays by observing the changes in the length of the output queue during the last 1 hour (by default);
- Detect when during the last hour (by default) packet errors occurred and why;
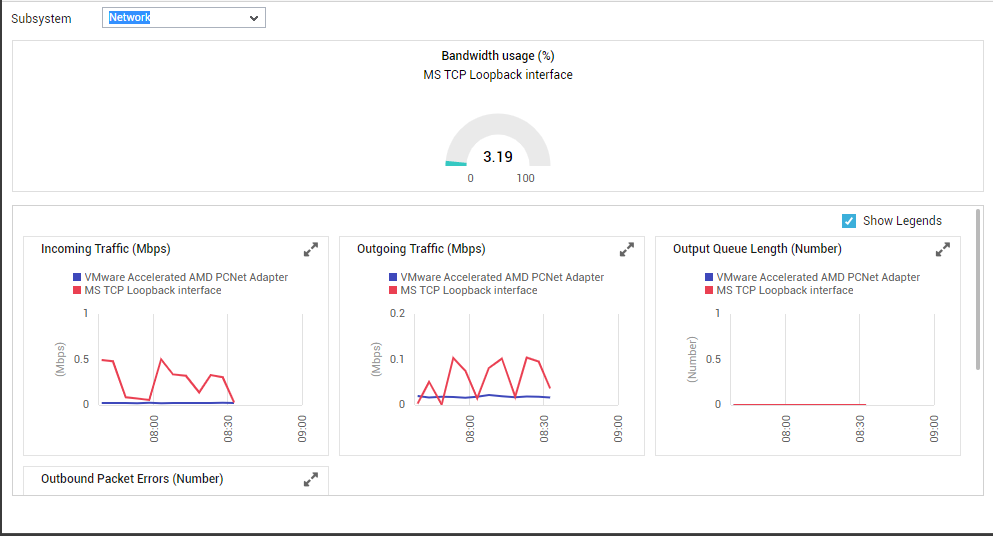
Figure 5 : Dashboard of the Network Subsystem
You can click on the
icon in any of the graphs here to enlarge it, alter the Timeline of that graph in its magnified mode, or pick a different Top-N or Last-N option -
Tcp
Selecting Tcp as the Subsystem results in the display of time-of-day graphs on the Tcp connectivity of the chosen VM; these graphs, which are plotted for a default period of 1 hour, reveal the following:
-
How has the Tcp load on the VM varied during the last 1 hour (by default)? Were there sporadic surges in load during the given period - if so, when did these spikes occur? If not, was a more consistent increase in load noticed during the last hour?
-
Were too many Tcp connections suddenly dropped from the listen queue? Could it because of a Tcp overload on the VM?
-
Did any Tcp connections fail during the default period? If so, when?
-
Was the Tcp retransmit ratio optimal during the last 1 hour?
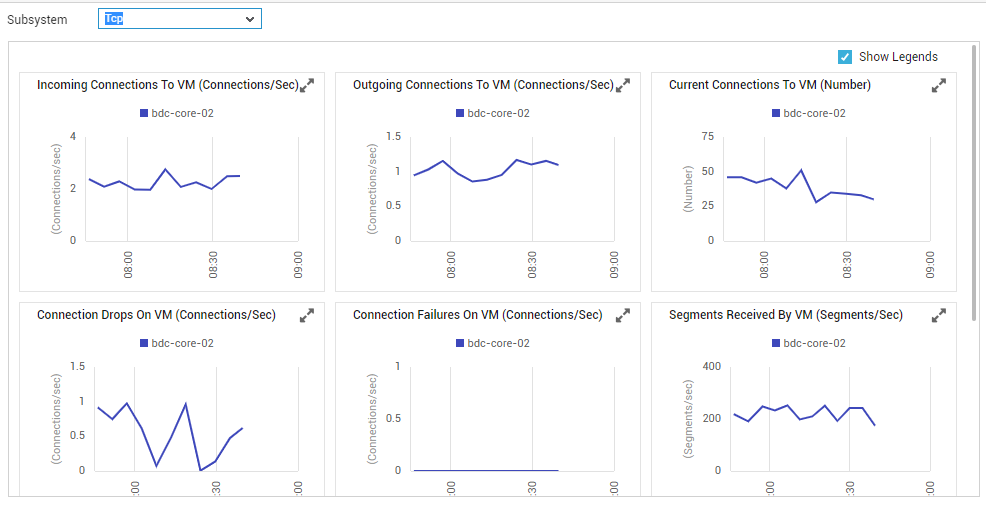
Figure 6 : Dashboard of the Tcp Subsystem
You can click on the icon in any of the graphs here to enlarge it, and can even alter the Timeline of that graph in its magnified mode.