

A few weeks ago, on 20th October 2025, AWS suffered a widespread outage in its US-EAST-1 region that affected a large number of customers globally. More than 1,000 apps and websites were impacted including major banks and popular games, streaming and social platforms such as WhatsApp, Snapchat, Fortnite and Pokémon Go.
The incident was widely reported, see:
- AWS’ 15-Hour Outage: 5 Big AI, DNS, EC2 And Data Center Keys To Know
- Amazon services ‘recovering’ as Snapchat and banks among sites hit by outage – BBC News
- What caused the AWS outage – and why did it make the internet fall apart? – BBC News
- What caused Amazon’s AWS outage, and why did so many major apps go offline? | Internet News | Al Jazeera
A large list of the affected apps and sites was recorded in a Sky News article that really cements the scale and visibility of the outage that impacted millions of end users (over 4 million end users reported issues via Downdetector) trying to use apps and access services (see: What’s affected by internet outage – all we know so far | Science, Climate & Tech News | Sky News).
eG Innovations is an AWS well-architected framework SaaS provider and we host a number of our SaaS services on AWS. These service are engineered in collaboration with Amazon to adhere to their best practices for resilience and security. Like all those other key customers, we were impacted and had to work with effects of the outage whilst Amazon worked to rectify the issue.
While monitoring our AWS services, we captured data around the outage that provided visibility on the issue and allowed us to make data-driven assessments of the situation. In this article we will share what we saw and what lessons you can take from this AWS outage to improve your resilience when designing services reliant on AWS and how to monitor critical AWS services to your benefit.
What Happened to AWS Services on 20th October 2025?
On 20 October 2025, AWS suffered a major outage that affected a wide range of websites, apps and services globally.
The incident began at around 3:11AM ET (12:11AM PDT) (early morning on 20 October) with AWS reporting “increased error rates and latencies” for multiple services in its US-EAST-1 region (Northern Virginia).
The root cause was eventually identified as a DNS (Domain Name System) resolution issue affecting the AWS internal infrastructure, particularly related to the Amazon DynamoDB API endpoint and other dependent services.
AWS stated that services were “fully returned to normal operations” by around 6:01PM ET (3:01PM PDT), i.e. a 15 hour outage was experienced.
Because the US-EAST-1 region is a major hub for AWS services, many other services relied on it by default; when the DNS resolution for DynamoDB and associated services failed, the effect cascaded to many dependent applications.
The incident highlighted the heavy dependency of modern internet services on a small number of cloud infrastructure providers, and how a failure in one major region can ripple widely.
Full details of the timelines and technicalities are available on Amazon’s AWS Health Portal, see: Service health – Oct 23, 2025 | AWS Health Dashboard | Global. The incident impacted 141 AWS services and caused connectivity issues in multiple services such as Lambda, DynamoDB, and CloudWatch. This is particularly relevant to this article as CloudWatch is Amazon’s native monitoring service for AWS and indeed one service we integrate with to give visibility on AWS for our customers.
How the AWS Outage Manifested in eG Enterprise
The eG Enterprise Monitoring solution does not rely on DynamoDB, where the primary issue arose, but was impacted by the effects to services impacted as a secondary effect. Secondary effects that also meant that the data from AWS CloudWatch was unable to report the issues. Monitoring relying on CloudWatch was effectively rendered useless by this point.
At 5:20AM ET (2:20AM PDT) eG Enterprise started to detect AWS issues. EBS volumes changed to an abnormal state.
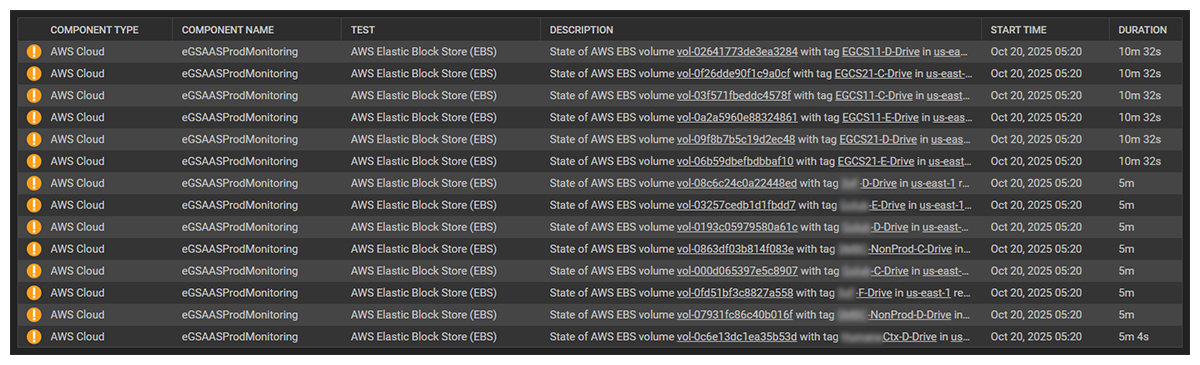
Within a short time, monitoring of our EC2 instances showed volumes being disconnected. This impacted applications and raised incidents in our service desk automatically. Meanwhile, Amazon were reporting that they had resolved the DynamoDB DNS issue but that issues had begun occurring in the “internal subsystem of EC2 that is responsible for launching EC2 instances due to its dependency on DynamoDB,”.

We also noticed that while some of the EBS volumes recovered, several others remained off for hours as reported by CloudWatch.
Synthetic Monitoring of AWS
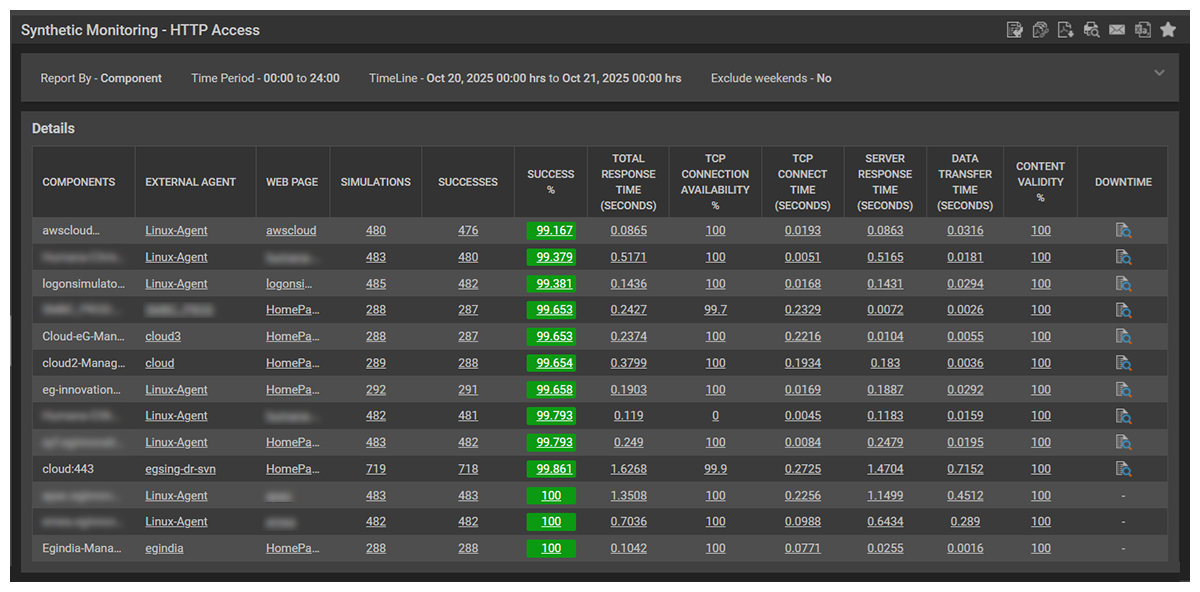
We proactively use eG Enterprise’s synthetic monitoring features to continually test and probe the user experience of our SaaS services. Simulated (“robot”) users attempt to use our SaaS services to probe the experience external customers are receiving. This testing allowed us to assess the impact of the AWS outages on our customers.
Our synthetic monitoring showed only a small impact on our SaaS services even when CloudWatch reported to show the volumes to be down for several hours. We also had agents deployed within our EC2 instances and they also indicated that the OS drives were indeed working and available. With the benefit of the retrospective information from Amazon, it seems that CloudWatch struggled to handle the deluge of alerts caused by the outage and was updating metrics extremely slowly. So, even though our services were working, CloudWatch continued to show alerts for EBS services.
Email Alerting – The Importance of a Backup System
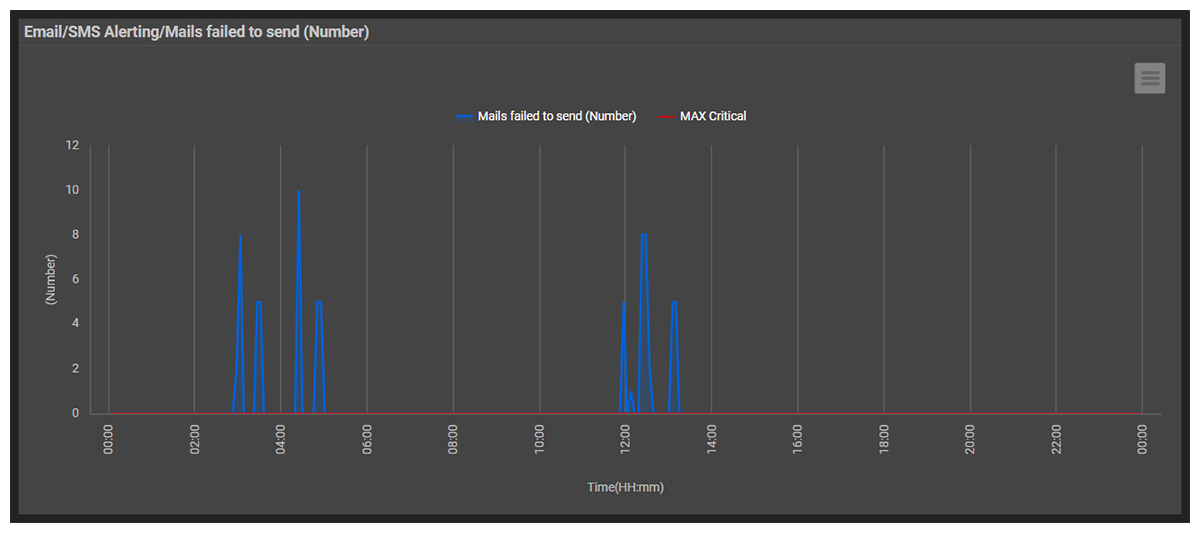
While all of our systems remained up, some of our services were impacted. Email alerting on our affected SaaS systems was also configured to use AWS SES on US-EAST1 and this service remained down for a while longer.
Relying on any cloud-based email system for monitoring alerting is a classic gotcha that many overlook. Outlook via Microsoft 365 is similarly vulnerable to Azure cloud outages (an issue covered in a previous article, see: Is M365 Down? – Proactive Alerting of a Microsoft Azure Outage).
eG Enterprise is designed to allow secondary email services to provide failover resilience and during this recent AWS outage our email alerting continued via a backup mail service configured to use SES on US-EAST2 to ensure that no email alerts were lost.
Lessons Learned
From the above postmortem of the October 20th AWS outage there are a few takeaways demonstrated for monitoring cloud systems and SaaS services reliant on cloud infrastructure, namely:
- Do not limit your observability to one source or cloud native monitoring. The CloudWatch information was not trustworthy during and for a few hours post the outage.
- Ensure that you are monitoring key SaaS services using synthetic monitoring so you know what exactly your users are seeing. This is in fact, the best way to measure your performance vs. SLAs (Service Level Agreements).
- Have agents on the cloud instances, this allowed us to cross-check the results that synthetic monitoring were collect. We could have logged in manually and checked, but that would have been a slow process and taken us hours to confirm.
- Always ensure key services have a fallback mechanism in place. In this example, having a backup email alerting configuration helped avoid an incident.
eG Enterprise is an Observability solution for Modern IT. Monitor digital workspaces,
web applications, SaaS services, cloud and containers from a single pane of glass.
Related Information
If you enjoyed this article, you might like to explore some other articles we have written about cloud outages:
eG Enterprise is an Observability solution for Modern IT. Monitor digital workspaces,
web applications, SaaS services, cloud and containers from a single pane of glass.
- Is Azure Down? – Proactive Alerting for Azure Outages | – A similar postmortem of an outage experienced by Microsoft’s Azure Cloud
- Is M365 Down? – Proactive Alerting of a Microsoft Azure Outage – A deep-dive into Azure outage considerations for those using Office 365 / Microsoft 365
- How to Protect your IT Ops from Cloud Outages – A guide to best practices and methodologies for resilient cloud monitoring that protect against failures and provide redundancy during cloud outages and cloud native monitoring failures.
- For information on how we certify products in partnership with AWS, see: eG Innovations achieves Amazon Web Services (AWS) Digital Workplace Competency status
 Karthik Ganesan is a Systems Manager at eG Innovations, he has worked out of our R&D office in Chennai for over 10 years. Karthik started his career as a hands-on network engineer and has particular empathy for those involved in frontline customer support.
Karthik Ganesan is a Systems Manager at eG Innovations, he has worked out of our R&D office in Chennai for over 10 years. Karthik started his career as a hands-on network engineer and has particular empathy for those involved in frontline customer support. 


