Root-cause analysis (RCA) has its roots in incident management, but reports of RCA’s demise may be greatly exaggerated. Being able to proactively identify the sources of event storms and performance anomalies will require automated, real-time root-cause analysis.
Root-cause analysis (RCA) has its roots in incident management, but reports of RCA’s demise may be greatly exaggerated. Being able to proactively identify the sources of event storms and performance anomalies will require automated, real-time root-cause analysis.
I think Enterprise Management Associates said it well:
“The data and metrics collected at instrumentation points across the application ecosystem are essential to performance monitoring and root cause analysis.
However, analytics capable of transforming data and metrics into an application-focused report or dashboards are what separates actual application monitoring from relatively simple silo monitoring.
Analytics add the context necessary to understand the role of each moving part in the end-to-end execution environment, a viewpoint that is absolutely critical for rapid – and eventually automated – problem determination and resolution.
Without this context, these solutions would simply be operational data stores versus true tools capable of insight into application ecosystems.”
– Sturm, Rick; Pollard, Carol; Craig, Julie. Application Performance Management (APM) in the Digital Enterprise: Managing Applications for Cloud, Mobile, IoT and eBusiness
So, this is why we’re hearing so much about “analytics.” Root-cause analysis is, and should be, part of this discussion.
Root-cause analysis is an activity that identifies the root cause of an incident or problem. From a monitoring and event management perspective, the “root-cause” is the event that, when corrected, will clear other events which happen to be effects, rather than the actual cause of the event storm.
Almost all monitoring tools can enable some form of root-cause analysis. The question is, who is doing the analysis? Reducing event storms from 1,000’s of events to 10 events sounds good, but it still doesn’t provide actionable information. In addition, providing charts and graphs that require specialized skills to analyze is not the same as automated root-cause analysis.
IT will need to compete with the business for data science and analytics skill sets, and it’s likely that demand will exceed supply for some time[i]. So, the need for automated diagnostics is what’s driving the analytics frenzy—particularly from an IT analytics perspective. Most organizations would rather spend their precious analytics talent on business analytics, so it’s likely that’s where the talent will reside.
But I wonder if IT can borrow from the business here. The term “embedded analytics” is used mostly in business process or business intelligence circles. Embedded analytics integrates analytic content and capabilities within a process:
- It provides relevant information and analytical tools designed for a specific task
- It provides information the context of a decision or action
- It enables more efficient use of applications by users
Let’s see how this applies to managing the performance of digital business services.
Task-Specific Information
A simple example of task-specific information is how the monitor presents alarm data. If you are presented with a topology map or an alarm window that shows multiple red/critical alarms, it is likely that multiple resources will become involved.
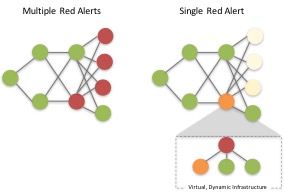 Ideally the interface will point the user to a single root-cause, even if it’s inside a public or private cloud infrastructure.
Ideally the interface will point the user to a single root-cause, even if it’s inside a public or private cloud infrastructure.
If the root-cause is in the application code, the interface should point you to the specific line of code that’s causing the performance issue (i.e., a database query, an application bug, etc.).
So, this type of visualization directly addresses a basic IT operations task.
Context-Specific Information
Application performance analytics also must be context-specific. Context is what gives us the setting or circumstances associated with events; it allows us to fully understand and assess what’s happening.
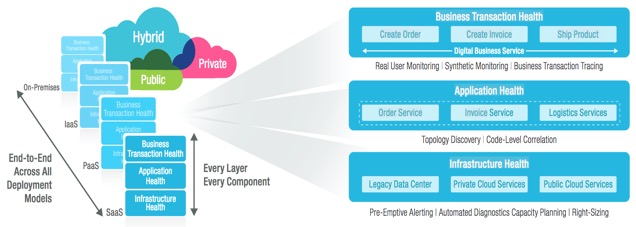
This applies to understanding business impacts in a production environment, but also to different use cases across the service lifecycle. Providing all stakeholders with a unified view in the context of a specific digital business service – with real-time intelligence at every layer of every component – is what unified monitoring is all about.
A converged application and infrastructure solution can provide high levels of automation, including end-to-end and top-to-bottom correlation and self-healing capabilities (automated remediation) for critical applications and their supporting infrastructure.
Context must include the entire digital business service ecosystem, inclusive of all its components, and automatically determine if an application slowdown is due to code level issues or due to infrastructure issues.
Root-Cause Analysis and Efficient APM Analytics
By combining application analytics capabilities – such as real user monitoring – transaction tracing and code-level diagnostics with automated root-cause analysis, customers can realize a level of automated diagnosis that can make troubleshooting and problem identification fast and definitive. This is the key to efficiency in application performance monitoring across all stages of the service lifecycle.
APM and Digital Business Services
The lines between business and IT analytics are blurring. But, as analytics become embedded into new digital business service applications, IT will still need the ability to proactively isolate the source of application performance issues. The machine learning and pattern matching that many business analytic tools provide may not have sufficient domain knowledge to enable this.
About eG Innovations
eG Innovations is a provider of performance management solutions. eG Enterprise takes measurements at every layer of every component across end-to-end IT services, learns the norms of all measurements and, through patented analytics embedded in the monitor, automatically isolates which layer of which component is the source of a performance issue.
Today we accomplish this across any deployment model— public, private or hybrid cloud—and from code to bare metal.
Learn more about eG Enterprise »
[i]IBM Predicts Demand For Data Scientists Will Soar 28% By 2020, Forbes – Louis Columbus , CONTRIBUTOR
eG Enterprise is an Observability solution for Modern IT. Monitor digital workspaces,
web applications, SaaS services, cloud and containers from a single pane of glass.