


Choice of EC2 Instance Can Adversely Impact Application Performance
Summary
It is incumbent on cloud operations teams to choose the correct type of AWS EC2 instance relative to the underlying application. The wrong choice could adversely impact business and user experience.
This article walks through a customer case study where the EC2 instance choice impacted their business. It is important for application and operations (AppOps) teams to collaborate closely in understanding the workload characteristics and performance expectations while also keeping cloud cost implications in mind. Setting the right alarms and taking corrective actions is also key for AppOps teams for delivering successful applications in the cloud.
 We were recently approached by a SaaS service provider to assist with a performance issue they had encountered with a web-based application. They were looking to expand their service but had been experiencing intermittent performance issues followed by near-catastrophic gridlocks with their deployment on AWS cloud.
We were recently approached by a SaaS service provider to assist with a performance issue they had encountered with a web-based application. They were looking to expand their service but had been experiencing intermittent performance issues followed by near-catastrophic gridlocks with their deployment on AWS cloud.
They were already using eG Enterprise for their on-premises infrastructure and applications and were looking to see if we could help them with their application performance issues on AWS cloud as well.
Their cloud operations/ site reliability engineering (SRE) team, however, were yet to start using eG Enterprise and were still using their legacy workflows reliant on native cloud tooling and asked us to help them track down their issue which had become business critical.
This article highlights how we were able to identify the issue. Interestingly, it was a combination of a software change and the impact it had upon their CPU credit balance of their AWS EC2 instances, which were using a burstable instance type (T2.xlarge).
A Quick Primer on EC2 Instances
Amazon Elastic Compute Cloud (EC2) is an IaaS offering from AWS using which customers can provision virtual machines (VMs) and infrastructure resources. AWS EC2 provides a wide selection of instance types optimized to fit different use cases.
Instance types are available in varying combinations of CPU, memory, storage, and networking capacity and give you the flexibility to choose the appropriate mix of resources for your applications. Each instance type includes one or more instance sizes, allowing you to scale your resources to the requirements of your target workload.

The list of EC2 instance types is available here. You can choose between:
- General Purpose
- Compute Optimized
- Memory Optimized
- Storage Optimized
- Accelerated Computing instance types
AWS EC2 CPU Credits explained – How are CPU credits used in EC2 T2 instances?
 The fundamental idea behind burstable instances is that a typical server has peaks and valleys in its performance baseline – it doesn’t run flat-out at the full utilization of 100%. If you had an opportunity to “bank” credits when your server is idle, you could save considerable money.
The fundamental idea behind burstable instances is that a typical server has peaks and valleys in its performance baseline – it doesn’t run flat-out at the full utilization of 100%. If you had an opportunity to “bank” credits when your server is idle, you could save considerable money.
CPU Credits allow EC2 instances to burst above an initial assigned CPU baseline of performance. The instance can earn and bank CPU credits while it is not running under load and burst above their initial CPU baseline as required.
CPU credits are a function of the number of CPUs, utilization and time
1 CPU credit = 1 vCPU * 100% utilization * 1 minute.
EC2 instances earn CPU credits continuously. The rate at which credits are earned depends on the instance size.
eG Enterprise can monitor AWS CPU credit usage on EC2 instances and alert you when CPU credits are running low. See screenshots in this blog.
As the name suggests, the General Purpose category is targeted toward general use cases and there are two broad EC2 families – the T family and the M family. The “t” stands for tiny and the “m” stands for micro or medium. Two of the most popular choices include:
- T2 instances, which are Burstable Performance Instances that provide a baseline level of CPU performance with the ability to burst above the baseline. There are also T3 instances which provide ability to burst but also have an unlimited mode by default to ensure performance during peak periods.
- M5 instances, which are the latest generation of General Purpose Instances. This family provides a balance of compute, memory, and network resources, and it is a good choice for many applications.
When choosing EC2, often, the initial choice of instance is a bit of a guess based on estimates or experience. Often, especially in pre-production, teams creating the instance types may not have prior experience of the application or its workload, especially at scale in production.
AWS EC2 Instance Selection
 In this case, considering the cost differences between T2 and M5 instances, a choice of the T2.xlarge had been made by the customer’s infrastructure team. The customer’s application team had specified the number of CPUs, RAM, and storage requirement but they were relatively new to the cloud and hence had not specified which instance type to use. The infrastructure team had been influenced by an internal discussion on the value proposition of burstable instances. They were aware that their production system was sized for peak demand, and that often, the demands on the system were lower and there had been a discussion about the business case for trying burstable instances. However, because they were reliant on native cloud monitoring tools, no real forecasting had been done and the organization had no experience of the issues they were about to encounter soon.
In this case, considering the cost differences between T2 and M5 instances, a choice of the T2.xlarge had been made by the customer’s infrastructure team. The customer’s application team had specified the number of CPUs, RAM, and storage requirement but they were relatively new to the cloud and hence had not specified which instance type to use. The infrastructure team had been influenced by an internal discussion on the value proposition of burstable instances. They were aware that their production system was sized for peak demand, and that often, the demands on the system were lower and there had been a discussion about the business case for trying burstable instances. However, because they were reliant on native cloud monitoring tools, no real forecasting had been done and the organization had no experience of the issues they were about to encounter soon.
The Application Slowness Issue
 The instances were commissioned, and applications deployed in pre-production for weeks, without any significant issues. The deployed applications had been deployed in many on-premises environments, and hence, were stable and well tested. There had been a few complaints of intermittent application sluggishness, but no significant performance challenges were observed in the pre-production pilot for several weeks. No new tickets were raised and the team running the system were under the impression that everything was working fine.
The instances were commissioned, and applications deployed in pre-production for weeks, without any significant issues. The deployed applications had been deployed in many on-premises environments, and hence, were stable and well tested. There had been a few complaints of intermittent application sluggishness, but no significant performance challenges were observed in the pre-production pilot for several weeks. No new tickets were raised and the team running the system were under the impression that everything was working fine.
After several weeks of operation, suddenly extreme slowness was observed with the application. There were many user complaints and clearly there was a significant problem at hand. Therefore, the customer’s application team decided to deploy eG Enterprise.
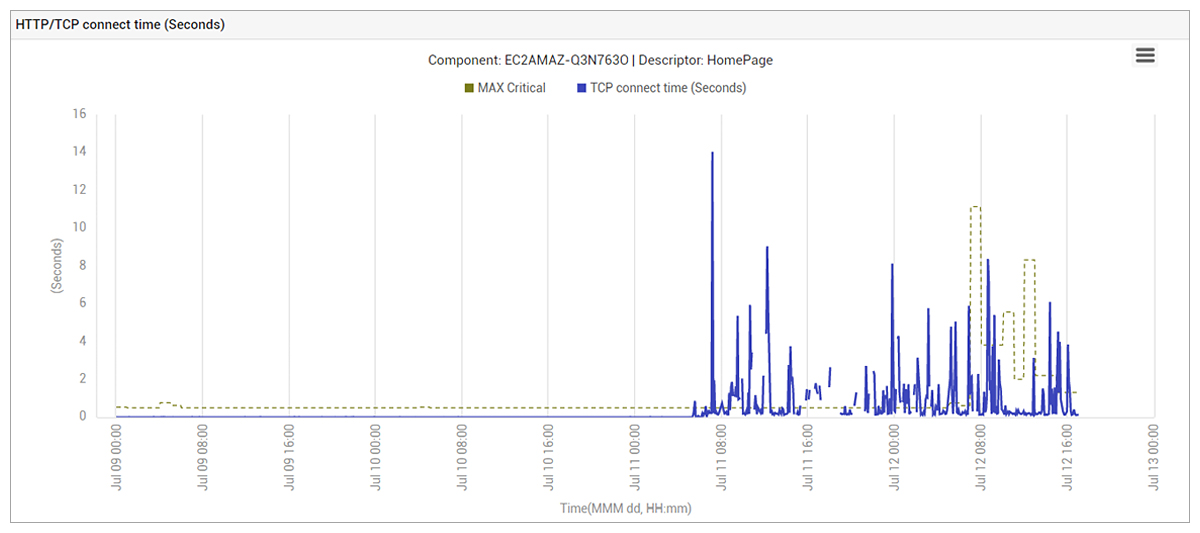
As the application being considered was a web application, eG Enterprise’s web protocol synthetic monitoring capability had been configured. The metrics reported by this monitor indicated several time periods where the application had been unavailable and cases of severe slowness. In the graph below, you can see that from July 11 onwards, web application response time had shot up from a few milliseconds to over 10 seconds at times.
Clearly, the problem was severe and was impacting the SLAs for the SaaS service.
Configuring End-to-End Monitoring of AWS and Application Performance
To provide additional diagnosis, the following monitoring capabilities were configured:
 The application team configured real user monitoring (RUM) to track what pages were accessed by users and how long the page load times were.
The application team configured real user monitoring (RUM) to track what pages were accessed by users and how long the page load times were.- They also monitored the backend database performance to see if any abnormalities in the database tier were causing application slowdowns.
- They also configured an agent inside the EC2 instance to track performance within the EC2 instance.
Troubleshooting the Web Application Slowness Issue
This section highlights how eG Enterprise helped identify and resolve the web application slowness issue.
The eG agent deployed within the EC2 instance immediately highlighted the severity of the problem. CPU usage was pegged at 100% for several hours, though we could not attribute this to one single application or process.
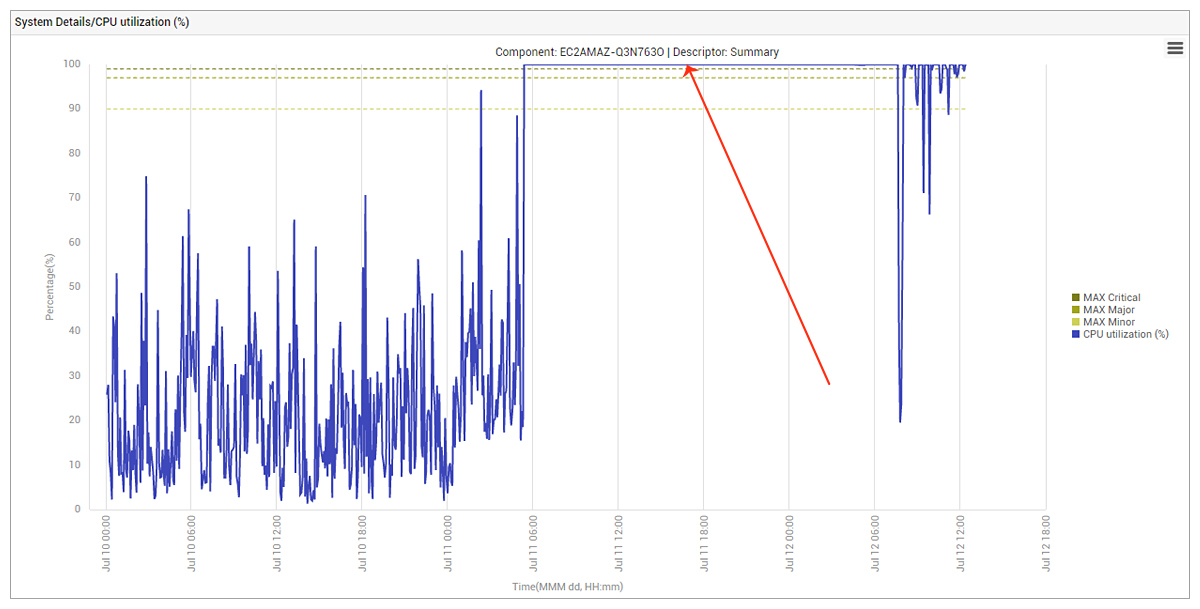
We also observed that eG Enterprise’s configuration and change tracking capability indicated that a new version of a threat protection software had been installed a few days before the problems had started Suspecting that this could have been the problem, the threat protection software was uninstalled. This immediately brought the CPU usage within the EC2 instance to the normal limit, as you can see in Figure 3.
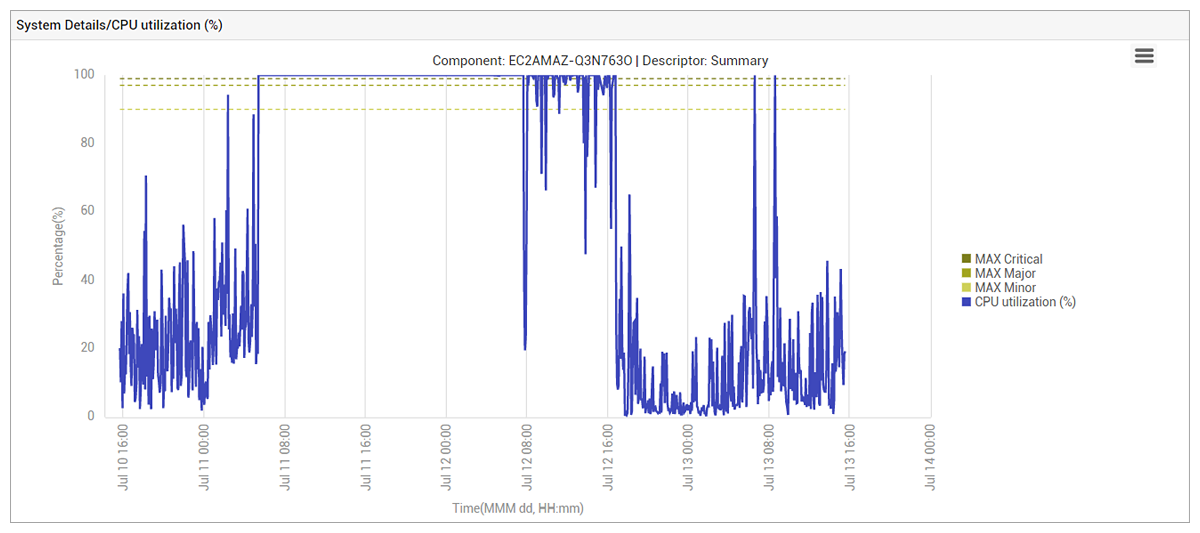
Given that the CPU usage inside the EC2 instance had dropped, we expected that the application performance would be back to normal. We could see normalcy for a few hours, but soon thereafter, performance issues were seen again, even though no unusual activity was seen within the EC2 instance. Not only was the web application slow to respond, but admin access to the system also was unbearably slow. Even typing a single character on the command line took seconds. There was no indication of the cause of the problem when looking at any of the metrics from within the EC2 instance.
Suspecting that the issue could be somewhere in the AWS infrastructure, we moved to the IT infrastructure team’s view. The infrastructure team had integrated AWS CloudWatch with eG Enterprise to track the performance of different EC2 services. Figure 4 below shows the type of metrics obtained using this integration.
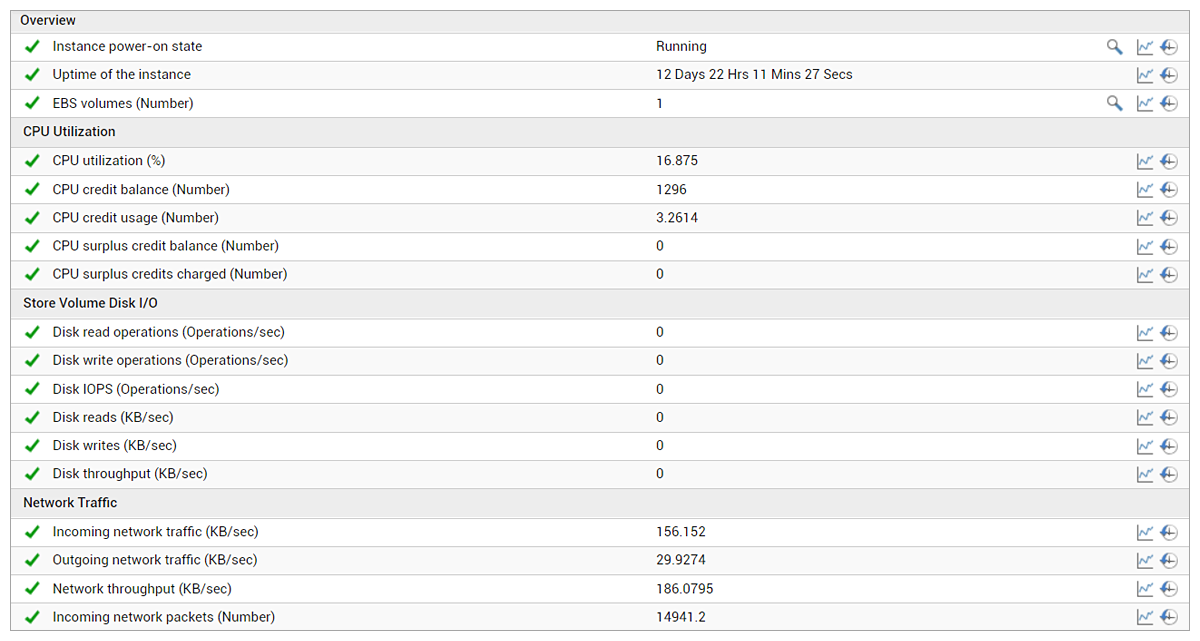
Analysis of the alerts in the eG Enterprise console enabled us to check on the CPU credit balance.

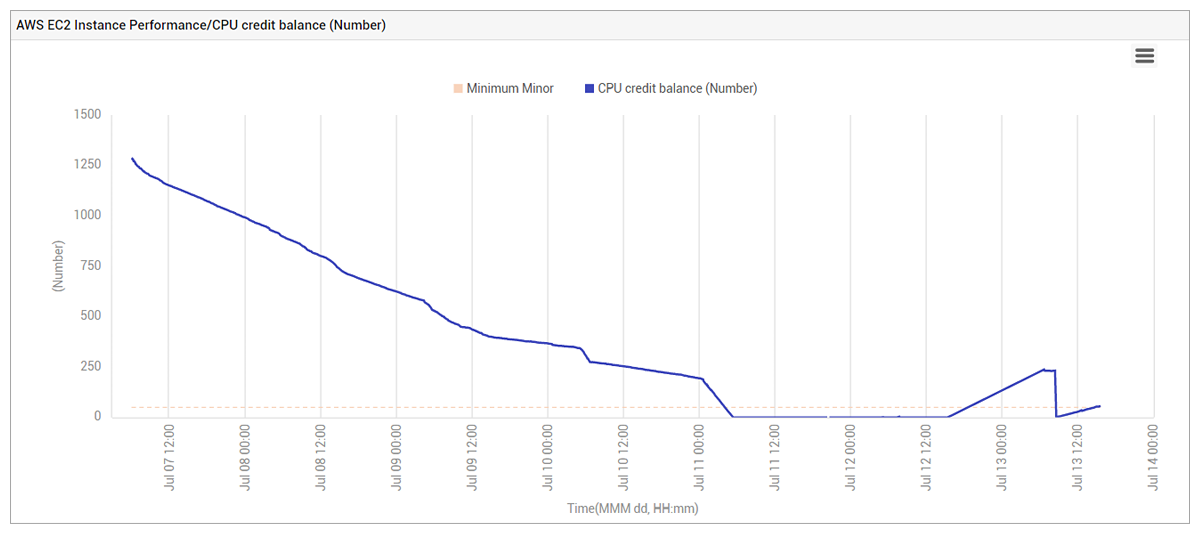
Figure 6 above shows that the EC2 instance’s CPU credit balance had been dropping continuously for several days – because of the increased CPU load caused by the threat protection software. When the CPU credit balance became 0, the workload on the EC2 instance was too much for it to handle with the CPU throttling done by AWS. This caused CPU usage within the EC2 instance to increase drastically. After the threat protection software was removed and the EC2 instance rebooted, the problem was still not resolved because the CPU credit balance remained very low for several hours. Until the credit balance reached an acceptable number (50+), the system remained almost unresponsive.
How burstable EC2 instances like the T2 series consume and accrue credit is covered very well in Understanding T2 Standard Instance CPU Credits (awsstatic.com).
Only after this analysis did the application team even become aware that the infrastructure team had provisioned a T2.xlarge instance for them with burstable capacity.

How the Customer Moved Forward
With their new understanding of the diagnosis of the issues, the customer took several subsequent steps:
- They contacted the security vendor and queried about the high CPU load and were advised on some configuration changes that improved the CPU usage.
- They were able to reintroduce the security software and baseline by using eG Enterprise to understand the CPU pattern of their application workload over time.
- Going forward, they will look at a structured benchmark of C and M series instances, T3.xlarge instances (higher baseline for bursting), and will explore the unlimited performance mode for burstable instances. Unlimited mode allows you to exceed the baseline of a burstable instance and charges you for the excess CPU cycles consumed; this is one metric that we have advised them to watch closely.
| Key points on Unlimited mode on burstable VMs : |
Key Takeaways
This example highlights several challenges faced by organizations, who are migrating applications to the cloud:
- Work collaboratively: Application and infrastructure teams must collaboratively work together to determine the type of AWS EC2 instance to be used. Just specifying the required CPU/memory is not sufficient.
-
Run a benchmark: Baseline application performance as accurately as possible and choose the AWS instance type based on that data. T2/T3/T4 instances are cheaper than M and C types but there are challenges if the burst usage exceeds the capacity limit.
When choosing a T2/T3/T4 instance, there is an unlimited performance mode setting for instances – https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/burstable-performance-instances-unlimited-mode.html You can decide to enable this (at a cost) to ensure that you don’t get into the situation we discussed in this case study.
- Outside-in & Inside-out: Problems with AWS instance slowness cannot be addressed by looking at metrics from within the EC2 instance VM. It is important to combine performance views from within the EC2 instance VM and the AWS-level insights. Configuration and change tracking is equally important to detect changes in the infrastructure and correlate with application performance issues.
- Set up alerts: Monitor your CPU credits and set up alarms when your credit balance becomes dangerously low. Even better, consider configuring an Autoscaling group so that it launches a new instance when your CPU credit is low or when your CPU usage is high for a threshold period.
- Be proactive: When a problem is rectified on-premises, you can expect your application and infrastructure to function well right after the problem is resolved. Our experience highlights that this is not always the case on the cloud. Hence, it is even more important that you monitor your cloud environments proactively and make sure that you do not let a problem escalate to a level where it impacts your business.
More information
- Information on eG Enterprise’s solutions for Amazon AWS: AWS Monitoring Solutions & Performance Tools | eG Innovations
Customer confidentiality : We have kept the details of the target infrastructure and the customer’s identity confidential, but with their permission, we have highlighted the challenge they faced and how it was solved so that the community at large can benefit from our experience.
eG Enterprise is an Observability solution for Modern IT. Monitor digital workspaces,
web applications, SaaS services, cloud and containers from a single pane of glass.
 Arun is Head of Products, Container & Cloud Performance Monitoring at eG Innovations. Over a 20+ year career, Arun has worked in roles including development, architecture and ops across multiple verticals such as banking, e-commerce and telco. An early adopter of APM products since the mid 2000s, his focus has predominantly been on performance tuning and monitoring of large-scale distributed applications.
Arun is Head of Products, Container & Cloud Performance Monitoring at eG Innovations. Over a 20+ year career, Arun has worked in roles including development, architecture and ops across multiple verticals such as banking, e-commerce and telco. An early adopter of APM products since the mid 2000s, his focus has predominantly been on performance tuning and monitoring of large-scale distributed applications. 




