


4 Key Metrics to Alert on Azure Load Balancer Issues
An Azure Load Balancer is a Layer-4 (TCP, UDP) load balancer that provides high availability by distributing incoming traffic among healthy VMs. A load balancer health probe monitors a given port on each VM and only distributes traffic to an operational VM. Azure Load Balancers are frequently used in Azure Virtual Desktop (AVD) deployments.
- eG Enterprise collects metrics and applies tests to help the administrator detect, diagnose, and resolve performance deficiencies related to the data traffic in the environment.
- eG Enterprise also reports the health probe status of the applications since the Load Balancer improves application uptime by probing the health of application instances, automatically taking unhealthy instances out of rotation, and reinstating them when they become healthy again.
- eG Enterprise also includes detailed diagnostics which provide additional problem insights to administrators, thereby easing troubleshooting.
From our work with Azure Load Balancer, we think there are 4 key metrics and events you should proactively monitor and alert on. For some metrics this should be when a usage threshold is crossed and for some events when a status code or availability level changes. These are events that the administrator should be aware of and are likely to cause IT problems and impact end users.
 | eG Enterprise is configured out-of-the-box to raise the alerts described. If you are using a system that requires manual configuration, we will give guidance on the threshold levels at which to set alerting. |
Information on adding Azure Load Balance metrics to Azure Log Analytics and Azure Monitor can be found in, Monitoring Azure Load Balancer | Microsoft Learn.
Microsoft provide some information on the multi-dimensional metrics available from Azure Load Balancers, advice on programmatic collection of metrics and advice on metric thresholds for alerting to avoid noise, see: Diagnostics with metrics, alerts, and resource health – Azure Load Balancer | Microsoft Learn.
4 Key Metrics to Alert on for Azure Load Balancer
-
Data path availability (%) – Indicates the data path availability from within a region to the load balancer front end.
A standard load balancer continuously uses the data path from within a region to the load balancer frontend, to the network that supports your VM. As long as healthy instances remain, the measurement follows the same path as your application’s load-balanced traffic. The data path in use is validated. The measurement is invisible to your application and doesn’t interfere with other operations.
A value of 100% indicates that the data path is very stable for the load balancer operations. A value of 0% indicates that the data path is unstable.
We would advise configuring a proactive automated immediate alert whenever the Datapath availability falls below 100%. If the metric for data path availability has reported less than 90% but greater than 25% health for at least two minutes the service is considered degraded, and you should expect that you will experience moderate to severe performance effect. Below 25% and the service is considered unavailable.
In the event of Datapath availability issues you may wish to consult the guidance in Troubleshoot Azure Load Balancer resource health, frontend, and backend availability issues | Microsoft Learn
-
Health probe status (%) – Indicates the health-probing status that monitors the application endpoint’s health.
A standard load balancer uses a distributed health-probing service that monitors your application endpoint’s health according to your configuration settings. This metric provides an aggregate or per-endpoint filtered view of each instance endpoint in the load balancer pool. You can see how load balancer views the health of your application, as indicated by your health probe configuration.
A very high value is desired for this measure. We would normally advise configuring a proactive automated immediate alert whenever the Health probe status falls below 100%.
Microsoft provides advice on troubleshooting in the event the Health probe status indicates issues, here: Troubleshoot Azure Load Balancer health probe status | Microsoft Learn.
-
Utilized SNAT ports (%)
A standard load balancer reports the number of outbound flows that are masqueraded to the Public IP address frontend. SNAT (Source Network Address Translation) ports are an exhaustible resource. This metric can give an indication of how heavily your application is relying on SNAT for outbound originated flows. Counters for successful and failed outbound SNAT flows are reported. The counters can be used to troubleshoot and understand the health of your outbound flows.
The default number of SNAT ports allocated per VM is 1024 but can be modified if needed and so an alert based on percentage (%) utilization is advised.
We would normally recommend raising an immediate minor alert or warning if the Utilized SNAT ports (%) exceeds 95% and a severe or critical alert if that usage reached 99% or higher.
Troubleshoot SNAT exhaustion and connection timeouts – Azure Load Balancer | Microsoft Learn
-
Provisioning state – Indicates the current Provisioning state of Load Balancer.
An Azure Load Balancer will have a Provisioning state associated that can take one of four values:
- Succeeded
- Updating
- Deleting
- Failed
eG Enterprise will raise an immediate alert if the Provisioning Status changes to Deleting or Failed. Whatever monitoring tool you leverage we would advise you to take a similar monitoring strategy.
Information on how to find the Provisioning state of an azure Load Balancer natively in Azure is given in Troubleshoot common issues Azure Load Balancer | Microsoft Learn (see under heading “Load Balancer in failed state”).
If your Azure Load Balancer is in a failed state, advice on rectifying the situation is given within Troubleshoot common deployment errors – Azure Load Balancer | Microsoft Learn.
 An Azure Load Balancer has encountered an issue causing an alert to be immediately raised in alarm
An Azure Load Balancer has encountered an issue causing an alert to be immediately raised in alarm
console notifying the administrator.
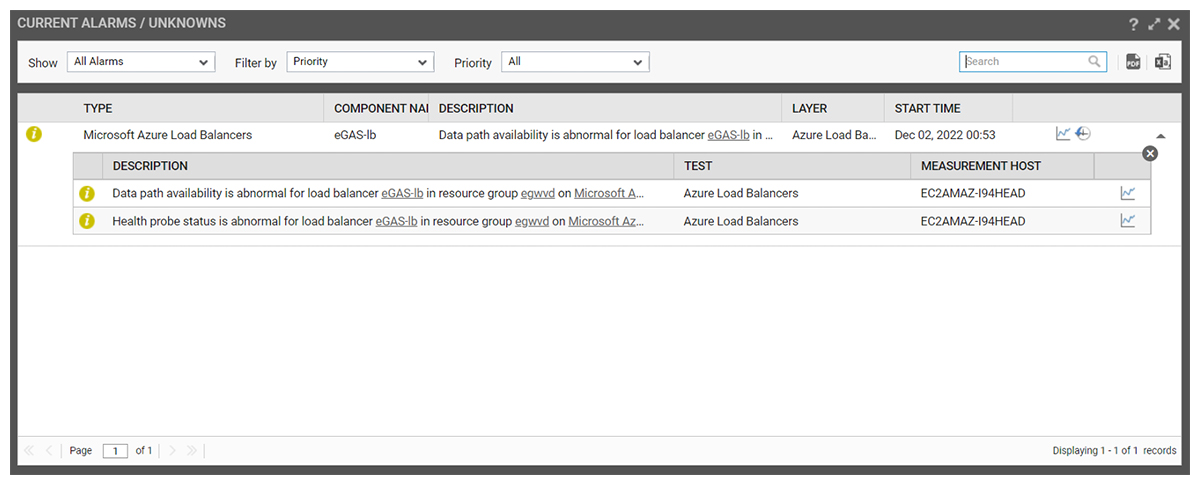
Other Metrics, Events and Configuration Data
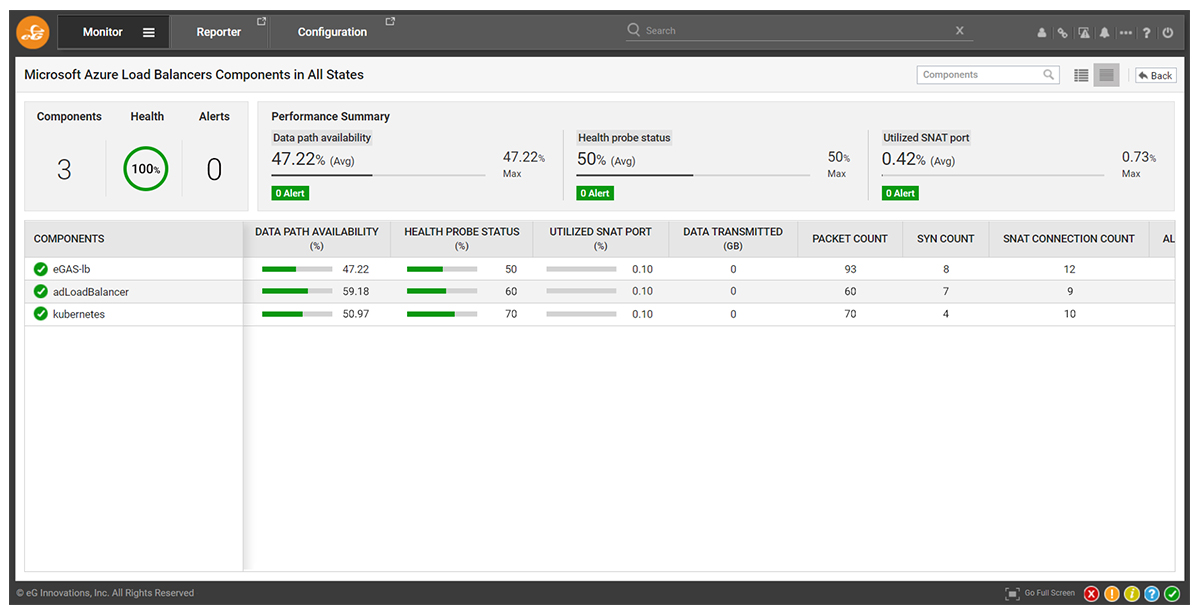
We continually collect other important metrics and data points about Azure Load Balancers. This is always available for administrators to view in the administrator console, on dashboards and via live and historical metrics. Administrators can easily:
- View graphs of recent and historical metrics. Instantly see whether issues are recurrent, normal usage patterns and so on
- Overview the health across all your Azure Load Balancers or groups of Load Balancers on easy-to-use rich dashboards, simple enough for help desk operators without Load Balancer domain experience to use
- Use historical data to capacity plan and understand long term trends and needs
- Optimize your Azure Load Balancer usage to minimize Azure Billing costs
The list of other metrics and data collected for an Azure Load Balancer includes:
- Data transmitted (MB)
- Packets (Number)
- SYNs (Number)
- SNAT connections (Number)
- Allocated SNAT ports (Number)
- Used SNAT ports (Number)
- Number of frontend IP configurations (Number)
- Number of backend pools (Number)
- Number of health probes (Number)
- Number of load balancing rules (Number)
- Number of inbound NAT rules (Number)
- Number of outbound rules (Number)
The SNAT connections metric describes the volume of successful and failed connections for outbound flows. Use SYN packets (Packet Count, SYN Count) metric to understand TCP connection attempts to your service.
Administrators with complex usage of Azure Load Balancers can refine the default alerting and configure additional alerting on any of the metrics and events collected by eG Enterprise beyond the default 4 key metrics. Both dynamic and static thresholds can be leveraged for anomaly and outlier detection and to provide alerting on unusual patterns of usage and behavior. See: Static vs Dynamic Alert Thresholds for Monitoring | eG Innovations for information on eG Enterprise’s thresholding capabilities.
Dashboard for Azure Load Balancers
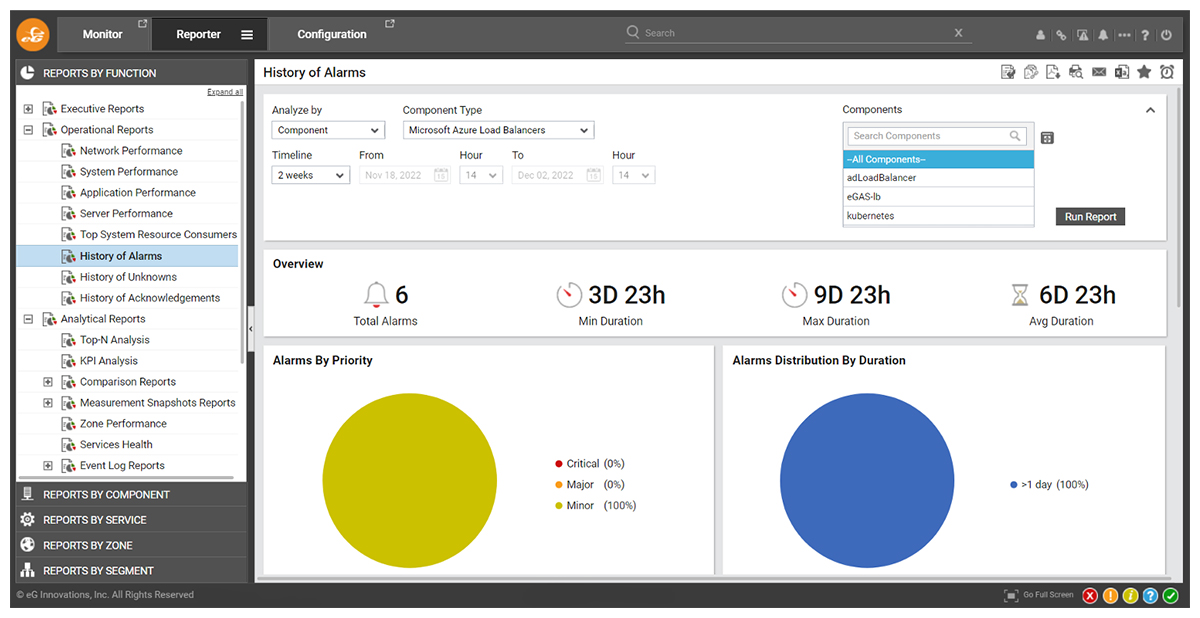
Live and Historical Reporting
Out-of-the-box reports allow administrators to instantly access overviews of the history of alerts associated with Azure Load Balancers on an individual or collective basis. Allowing administrators to understand patterns of behavior and problems.
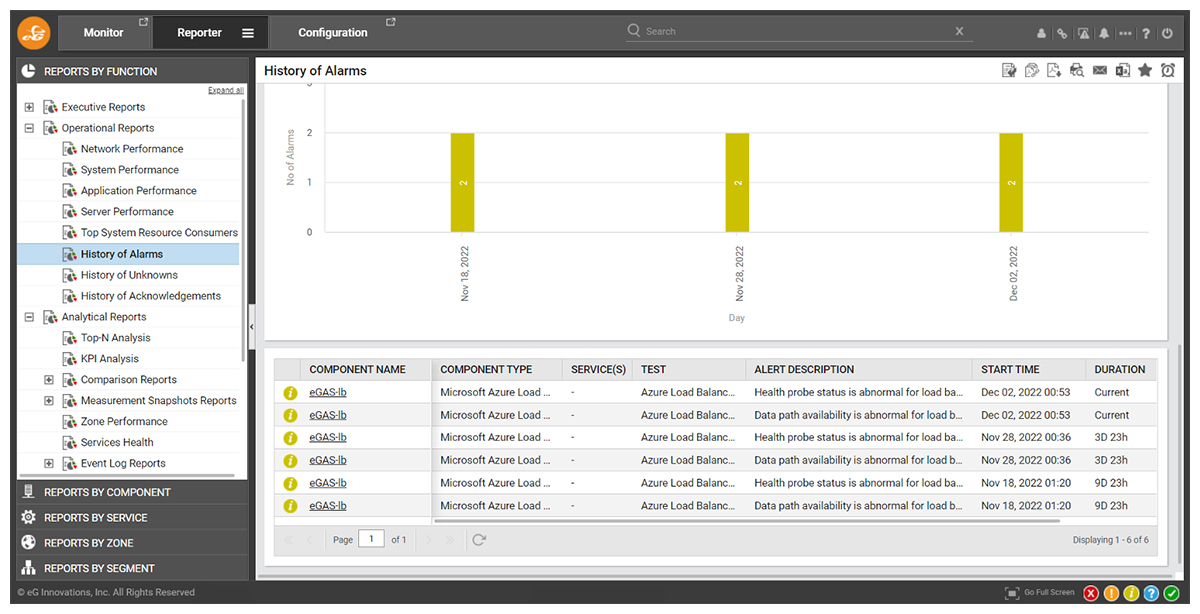
If you are using Azure Load Balancers in conjunction with other Azure Services you may be interested in my previous guides for troubleshooting other Azure Services such as Azure Active Directory (Azure AD) (see: How to monitor Azure AD Step by Step ) or Azure Virtual Desktop (see: Troubleshoot Slow Azure Virtual Desktop Logons and Monitor and investigate AVD Broker issues).
eG Enterprise is an Observability solution for Modern IT. Monitor digital workspaces,
web applications, SaaS services, cloud and containers from a single pane of glass.
Learn More
- Diagnostics with metrics, alerts, and resource health – Azure Load Balancer | Microsoft Learn
- Source Network Address Translation (SNAT) for outbound connections – Azure Load Balancer | Microsoft Learn
- If you are using Azure Load Balancers in conjunction with AVD, you will probably find my guide to AVD monitoring and troubleshooting useful, see: Ultimate guide to monitoring Azure Virtual Desktop Technology | White Paper
- Useful community articles for understanding the principles of SNAT Port Exhaustion include SNAT with App Service | 4lowTheRabbit.github.io and Azure load balancer SNAT behavior explained – Annotations to tcp port numbers reused, ACK with wrong sequence number plus RST from 3-way handshake and SNAT port exhaustion (msazure.club)
- Update 27th Feb 2023: There’s an excellent new post from Swetha Mudunuri (Community Azure Cloud Security Evangelist) detailing load balancing options in Azure: https://www.linkedin.com/posts/swethamudunuri_learning-connections-cloudnloud-activity-7035305621453201408-Qmeb?utm_source=share&utm_medium=member_desktop.
 Babu is Head of Product Engineering at eG Innovations, having joined the company back in 2001 as one of our first software developers following undergraduate and masters degrees in Computer Science, he knows the product inside and out. Based within our Singapore R&D Management team, Babu has undertaken various roles in engineering and product management becoming a certified PMP along the way.
Babu is Head of Product Engineering at eG Innovations, having joined the company back in 2001 as one of our first software developers following undergraduate and masters degrees in Computer Science, he knows the product inside and out. Based within our Singapore R&D Management team, Babu has undertaken various roles in engineering and product management becoming a certified PMP along the way. 
