What is Hadoop?
Hadoop is a framework that allows you to first store Big Data in a distributed environment, so that, you can process it parallely. Hadoop consists of the following core components:
-
Hadoop Distributed File System (HDFS): HDFS allows you to store data of various formats across a cluster. It creates an abstraction, similar to virtualization. You can see HDFS logically as a single unit for storing data, but actually you are storing your data across multiple nodes in a distributed fashion. HDFS follows master-slave architecture.
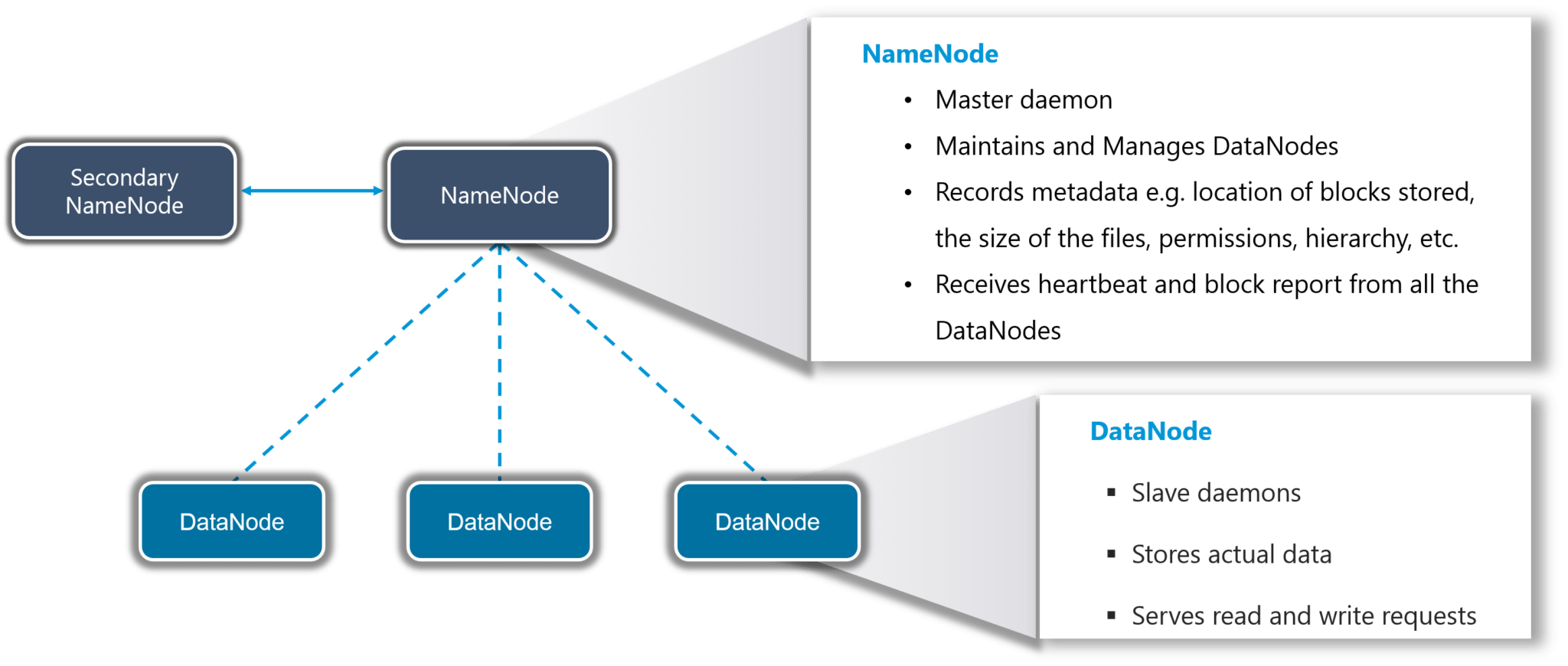
Figure 1 : The HDFS architecture
In HDFS, NameNode is the master node and DataNodes are the slaves. NameNode contains the metadata about the data stored in DataNodes, such as which data block is stored in which DataNodes, where are the replications of the data block kept etc. The actual data is stored in DataNodes.
The data blocks present in the DataNodes are also replicated for high availability; the default replication factor is 3. This means, that every data block will by default be replicated across three DataNodes. This way, if even one of the DataNodes fails, HDFS will still have two more copies of the lost data blocks in two other DataNodes.
Moreover, HDFS focuses on horizontal scaling. This way, you can always add more DataNodes to the HDFS cluster as and when required to expand its storage capacity, instead of scaling up the resources of your DataNodes.
Also, HDFS follows the write once and read many model. Due to this, you can just write the data once and you can read it multiple times for finding insights. Data processing is also faster, as the different slave nodes process the data parallely and then send the processed data to the master node; the master node merges the data received from the different slave nodes and sends the response to the client.
-
Yet Another Resource Negotiator (YARN): YARN performs all your processing activities by allocating resources and scheduling tasks.
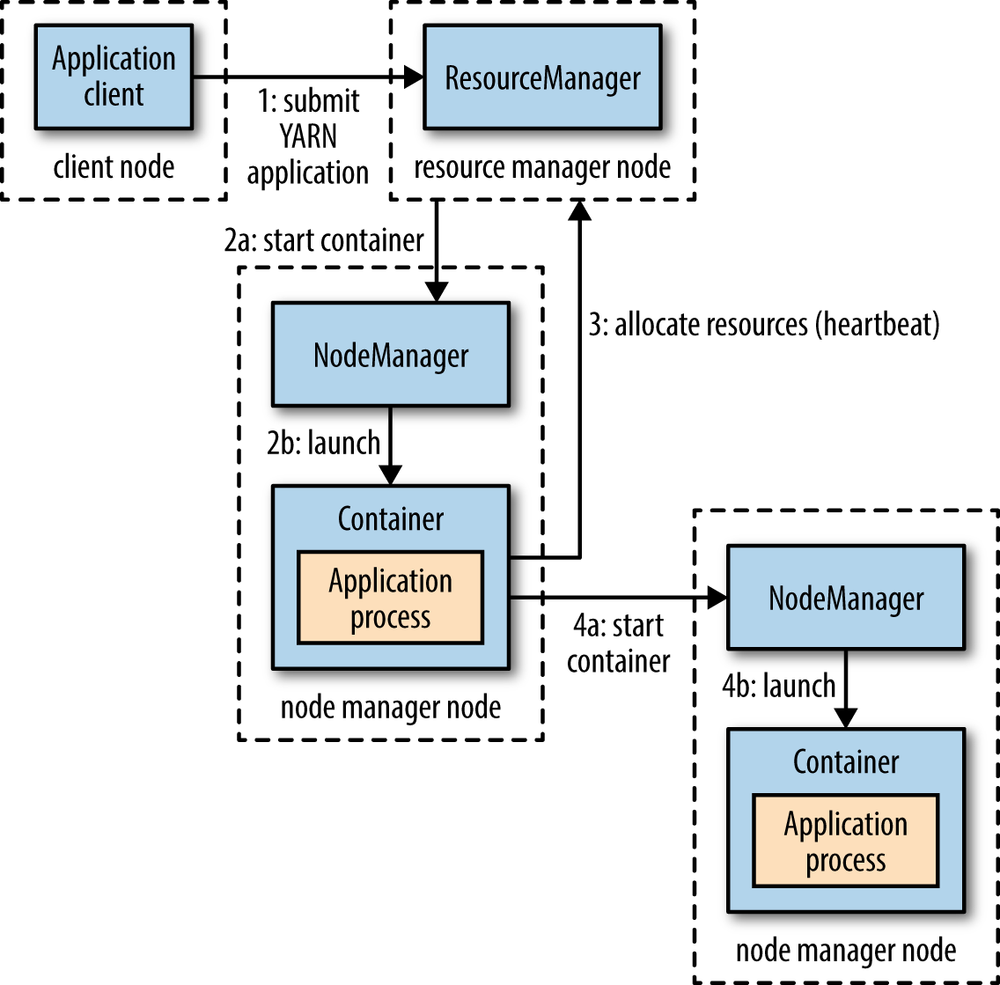
Figure 2 : YARN architecture
YARN performs all your processing activities by allocating resources and scheduling tasks.
ResourceManager is again a master node. It receives the processing requests and then passes the parts of requests to corresponding NodeManagers, where the actual processing takes place. NodeManagers are installed on every DataNode. It is responsible for the execution of the task on every single DataNode.