NVIDIA Grid GPUs Test
GPU-accelerated computing is the use of a graphics processing unit (GPU) together with a CPU to accelerate scientific, analytics, engineering, consumer, and enterprise applications. GPU-accelerated computing enhances application performance by offloading compute-intensive portions of the application to the GPU, while the remainder of the code still runs on the CPU.
Imagine if you could access to your GPU-accelerated applications anywhere on any device, even those requiring intensive graphics power. NVIDIA GRID makes this possible. With NVIDIA GRID, a virtualized GPU designed specifically for virtualized server environments, data center managers can bring true PC graphics-rich experiences to users.
The NVIDIA GRID GPUs will be hosted in enterprise data centers and allow users to run virtual desktops or virtual applications on multiple devices connected to the internet and across multiple operating systems, including PCs, notebooks, tablets and even smartphones. Users can utilize their online-connected devices to enjoy the GPU power remotely.
Virtual application delivery with XenApp and NVIDIA GRID™ offloads graphics processing from the CPU to the GPU, allowing the data center manager to deliver to all user types for the first time.
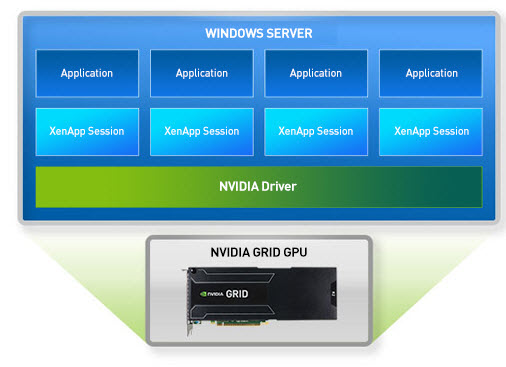
Figure 1 : An Architectural diagram for NVIDIA GRID with XenApp
In GPU-enabled Citrix XenApp environments, if users to virtual applications complain of slowness when accessing graphic applications, administrators must be able to instantly figure out what is causing the slowness – is it because adequate GPU resources are not available to the host? Or is it because of excessive utilization of GPU memory and processing resources by a few virtual applications on the host? Accurate answers to these questions can help administrators determine whether/not:
- The host is sized with sufficient GPU resources;
- The GPUs are configured with enough graphics memory;
Measures to right-size the host and fine-tune its GPU configuration can be initiated based on the results of this analysis. This is exactly what the Grid GPUs test helps administrators achieve!
Using this test, administrators can identify the physical GPUs on the NVIDIA GRID card used by the host. For each physical GPU, administrators can determine how actively memory on that GPU is utilized, thus revealing the GPU on which memory is used consistently. In addition, the test also indicates how busy each GPU is, and in the process pinpoints those physical GPUs that are being over-utilized by the virtual applications on the host. The adequacy of the physical GPU resources is thus revealed. Moreover, the power consumption and temperature of each GPU of the host is also monitored and its current temperature and power usage can be ascertained; administrators are thus alerted to abnormal power usage of the GPU and unexpected fluctuations in its temperature. The power limit set and the clock frequencies configured are also revealed, so that administrators can figure out whether the GPU is rightly configured for optimal processing or is any fine-tuning required.
Target of the test : A Citrix XenApp server
Agent deploying the test : An internal/remote agent
Outputs of the test : One set of results for each GRID physical GPU assigned to the host being monitored
| Parameters | Description |
|---|---|
|
Test Period |
How often should the test be executed. By default, this is 5 minutes. |
|
Host |
The host for which the test is to be configured. |
|
Port |
Refers to the port used by the Citrix server . |
|
NVIDIA Path |
Specify the full path to the install directory of the NVIDIA. By default, the NVIDIA will be installed in the C:/Progra~1/NVIDIA~1/NVSMI directory. If the NVIDIA indeed resides in its default location, set the NVIDIA Path to none. On the other hand, if the NVIDIA has been installed in a different location, provide the full path to that location against NVIDIA Path. |
| Measurement | Description | Measurement Unit | Interpretation | ||||||
|---|---|---|---|---|---|---|---|---|---|
|
GPU memory utilization |
Indicates the proportion of time over the past sample period during which global (device) memory was being read or written on this GPU. |
Percent |
A value close to 100% is a cause for concern as it indicates that graphics memory on a GPU is almost always in use. In a XenApp environment, this could be because one/more sessions to XenApp are consistently accessing graphic-intensive applications. In a Shared vGPU environment on the other hand, memory may be consumed all the time, if one/more VMs/virtual desktops on the host utilize the graphics memory excessively and constantly. If you find that only a single VM/virtual desktop has been consistently hogging the graphic memory resources, you may want to switch to the Dedicated GPU mode, so that excessive memory usage by that VM/virtual desktop has no impact on the performance of other VMs/virtual desktops on that host. If the value of this measure is high almost all the time for most of the GPUs, it could mean that the host is not sized with adequate graphics memory. |
||||||
|
Allocated frame buffer memory |
Indicates the amount of frame buffer memory on-board this GPU that has been allocated to the host. |
MiB |
Frame buffer memory refers to the memory used to hold pixel properties such as color, alpha, depth, stencil, mask, etc. Properties like the screen resolution, color level, and refresh speed of the frame buffer can impact graphics performance. Also, if Error-correcting code (ECC) is enabled on a host, the available frame buffer memory may be decreased by several percent. This is because, ECC uses up memory to detect and correct the most common kinds of internal data corruption. Moreover, the driver may also reserve a small amount of memory for internal use, even without active work on the GPU; this too may impact frame buffer memory. For optimal graphics performance therefore, adequate frame buffer memory should be allocated to the host. |
||||||
|
Unallocated frame buffer memory |
Indicates the amount of frame buffer memory on-board this GPU that has not been allocated to the host. |
MiB |
|
||||||
|
GPU compute utilization |
Indicates the proportion of time over the past sample period during which one or more kernels was executing on this GPU. |
Percent |
A value close to 100% indicates that the GPU is busy processing graphic requests almost all the time. In a XenApp environment, this could be because one/more sessions to XenApp are consistently accessing graphic-intensive applications. In a Shared vGPU environment on the other hand, a GPU may be in use almost all the time, if one/more VMs/virtual desktops on the host are running highly graphic-intensive applications. If you find that only a single VM/virtual desktop has been consistently hogging the GPU resources, you may want to switch to the Dedicated GPU mode, so that excessive GPU usage by that VM/virtual desktop has no impact on the performance of other VMs/virtual desktops on that host. If all GPUs are found to be busy most of the time, you may want to consider augmenting the GPU resources of the host. Compare the value of this measure across physical GPUs to know which GPU is being used more than the rest. |
||||||
|
Power consumption: |
Indicates the current power usage of this GPU. |
Watts |
A very high value is indicative of excessive power usage by the GPU. In such cases, you may want to enable Power management so that the GPU limits power draw under load to fit within a predefined power envelope by manipulating the current performance state. |
||||||
|
Core GPU temperature |
Indicates the current temperature of this GPU. |
Celsius |
Ideally, the value of this measure should be low. A very high value is indicative of abnormal GPU temperature. |
||||||
|
Total framebuffer memory |
Indicates the total size of frame buffer memory of this GPU. |
MiB |
Frame buffer memory refers to the memory used to hold pixel properties such as color, alpha, depth, stencil, mask, etc. |
||||||
|
Total BAR1 memory |
Indicates the total size of the BAR1 memory of this GPU. |
MiB |
BAR1 is used to map the frame buffer (device memory) so that it can be directly accessed by the CPU or by 3rd party devices (peer-to-peer on the PCIe bus). |
||||||
|
Allocated BAR1 memory: |
Indicates the amount of BAR1 memory on this GPU that is allocated to the host. |
MiB |
For better user experience with graphic applications, enough BAR1 memory should be available to the host. |
||||||
|
Unallocated BAR1 memory |
Indicates the total size of BAR1 memory of this GPU that is still not allocated to the host. |
MiB |
|
||||||
|
Power management |
Indicates whether/not power management is enabled for this GPU. |
|
Many NVIDIA graphics cards support multiple performance levels so that the server can save power when full graphics performance is not required. The default Power Management Mode of the graphics card is Adaptive. In this mode, the graphics card monitors GPU usage and seamlessly switches between modes based on the performance demands of the application. This allows the GPU to always use the minimum amount of power required to run a given application. This mode is recommended by NVIDIA for best overall balance of power and performance. If the power management mode is set to Adaptive, the value of this measure will be Supported. Alternatively, you can set the Power Management Mode to Maximum Performance. This mode allows users to maintain the card at its maximum performance level when 3D applications are running regardless of GPU usage. If the power management mode of a GPU is Maximum Performance, then the value of this measure will be Maximum. The numeric values that correspond to these measure values are discussed in the table below:
Note: By default, this measure will report the Measure Values listed in the table above to indicate the power management status. In the graph of this measure however, the same is represented using the numeric equivalents only. |
||||||
|
Power limit: |
Indicates the power limit configured for this GPU. |
Watts |
This measure will report a value only if the value of the ‘Power management’ measure is ‘Supported’. The power limit setting controls how much voltage a GPU can use when under load. Its not advisable to set the power limit at its maximum – i.e., the value of this measure should not be the same as the value of the Max power limit measure - as it can cause the GPU to behave strangely under duress. |
||||||
|
Default power limit |
Indicates the default power management algorithm's power ceiling for this GPU. |
Watts |
This measure will report a value only if the value of the ‘Power management’ measure is ‘Supported’. |
||||||
|
Enforced power limit |
Indicates the power management algorithm's power ceiling for this GPU. |
Watts |
This measure will report a value only if the value of the ‘Power management’ measure is ‘Supported’. The total board power draw is manipulated by the power management algorithm such that it stays under the value reported by this measure. |
||||||
|
Min power limit |
The minimum value that the power limit of this GPU can be set to. |
Watts |
This measure will report a value only if the value of the ‘Power management’ measure is ‘Supported’. |
||||||
|
Max power limit |
The maximum value that the power limit of this GPU can be set to. |
Watts |
This measure will report a value only if the value of the ‘Power management’ measure is ‘Supported’. If the value of this measure is the same as that of the Power limit measure, then the GPU may behave strangely. |
||||||
|
Graphics clock |
Indicates the current frequency of the graphics clock of this GPU. |
MHz |
GPU has many more cores than your average CPU but these cores are much simpler and much smaller so that many more actually fit on a small piece of silicon. These smaller, simpler cores go by different names depending upon the tasks they perform. Stream processors are the cores that perform a single thread at a slow rate. But since GPUs contain numerous stream processors, they make overall computation high. The streaming multiprocessor clock refers to how fast the stream processors run. The Graphics clock is the speed at which the GPU operates. The memory clock is how fast the memory on the card runs. By correlating the frequencies of these clocks (i.e., the value of these measures) with the memory usage, power usage, and overall performance of the GPU, you can figure out if overclocking is required or not. Overclocking is the process of forcing a GPU core/memory to run faster than its manufactured frequency. Overclocking can have both positive and negative effects on GPU performance. For instance, memory overclocking helps on cards with low memory bandwidth, and with games with a lot of post-processing/textures/filters like AA that are VRAM intensive. On the other hand, speeding up the operation frequency of a shader/streaming processor/memory, without properly analyzing its need and its effects, may increase its thermal output in a linear fashion. At the same time, boosting voltages will cause the generated heat to sky rocket. If improperly managed, these increases in temperature can cause permanent physical damage to the core/memory or even “heat death”. Putting an adequate cooling system into place, adjusting the power provided to the GPU, monitoring your results with the right tools and doing the necessary research are all critical steps on the path to safe and successful overclocking. |
||||||
|
Streaming multiprocessor clock |
Indicates the current frequency of the streaming multiprocessor clock of this GPU. |
MHz |
|||||||
|
Memory clock |
Indicates the current frequency of the memory clock of this GPU. |
MHz |
|||||||
|
Fan speed |
Indicates the percent of maximum speed that this GPU’s fan is currently intended to run at. |
Percent |
The value of this measure could range from 0 to 100%. An abnormally high value for this measure could indicate a problem condition – eg., a sudden surge in the temperature of the GPU that could cause the fan to spin faster. Note that the reported speed is only the intended fan speed. If the fan is physically blocked and unable to spin, this output will not match the actual fan speed. Many parts do not report fan speeds because they rely on cooling via fans in the surrounding enclosure. By default the fan speed is increased or decreased automatically in response to changes in temperature. |
||||||
|
Compute processes |
Indicates the number of processes having compute context on this GPU. |
Number |
Use the detailed diagnosis of this measure to know which processes are currently using the GPU. The process details provided as part of the detailed diagnosis include, the PID of the process, the process name, and the GPU memory used by the process. Note that the GPU memory usage of the processes will not be available in the detailed diagnosis, if the Windows platform on which XenApp operates is running in the WDDM mode. In this mode, the Windows KMD manages all the memory, and not the NVIDIA driver. Therefore, the NVIDIA SMI commands that the test uses to collect metrics will not be able to capture the GPU memory usage of the processes. |
||||||
|
Volatile single bit errors |
Indicates the number of volatile single bit errors in this GPU. |
Number |
Volatile error counters track the number of errors detected since the last driver load. Single bit ECC errors are automatically corrected by the hardware and do not result in data corruption. Ideally, the value of this measure should be 0. |
||||||
|
Volatile double bit errors |
Indicates the total number of volatile double bit errors in this GPU. |
Number |
Volatile error counters track the number of errors detected since the last driver load. Double bit errors are detected but not corrected. Ideally, the value of this measure should be 0. |
||||||
|
Aggregate single bit errors |
Indicates the total number of aggregate single bit errors in this GPU. |
Number |
Aggregate error counts persist indefinitely and thus act as a lifetime counter. Single bit ECC errors are automatically corrected by the hardware and do not result in data corruption. Ideally, the value of this measure should be 0. |
||||||
|
Aggregate double bit errors |
Indicates the total number of aggregate double bit errors in this GPU. |
Number |
Aggregate error counts persist indefinitely and thus act as a lifetime counter. Double bit errors are detected but not corrected. Ideally, the value of this measure should be 0. |