


How Java Applications Access Databases?
Most modern enterprise applications are multi-tiered:
- One or more web front-ends balance requests across multiple servers for scalability.
- Middleware application servers host the business logic.
- The data resides in backend database servers and is accessed by application logic hosted on the application servers.
- The applications may also rely on external services – for authentication, for payment processing, shipping, and other such services.
While tuning the performance of your application at the code level or sizing the JVM appropriately are important for enhancing performance, it is equally important to look at how to tune accesses to the backend database. After all, response time for a web request is dependent on the processing time in the Java application tier as well as the query processing time in the database tier.
Importance of Database Performance for Java ApplicationsA JRebel survey of the performance of Java applications found that a huge proportion of Java application performance issues centered around the database:
|
When they are called to troubleshoot application slowness, Java application developers often complain that ’It’s the database’ which is slow. Is this really the case, or could you have improved the way your application was written to get better performance when accessing the database server?
In this blog, we recommend six tips that you can use to enhance Java application performance by tuning database accesses from your application. All of these are changes you can make in your application without requiring any special changes in the database server settings or additional configurations on the database server:
1. Follow Common JDBC Best Practices
| What is JDBC? JDBC stands for Java Database Connectivity, which is a standard Java API for database-independent interactions between the Java programming language and a wide range of databases. Queries could be selects, inserts, deletes, etc. Java applications use JDBC drivers to connect with the database server/instance. |
For best application performance, make sure you are following JDBC best practices, wherever possible, in your applications. There are several common best practices documented widely:
 Make sure you are using the latest version of the database driver that is compatible with your JRE and database server: All Java applications use a database driver. A JDBC driver is a software component enabling a Java application to interact with a database. Depending on your database server type, there may be multiple choices for the JDBC driver. In such a case, use performance tests to determine which driver works best for your workload. At the same time, make sure that you are choosing the latest version of the database driver that is compatible with the JRE you are using and the database server version that is being accessed. Incompatibilities between the JDBC driver, the JRE, and the database server versions can impact application performance.
Make sure you are using the latest version of the database driver that is compatible with your JRE and database server: All Java applications use a database driver. A JDBC driver is a software component enabling a Java application to interact with a database. Depending on your database server type, there may be multiple choices for the JDBC driver. In such a case, use performance tests to determine which driver works best for your workload. At the same time, make sure that you are choosing the latest version of the database driver that is compatible with the JRE you are using and the database server version that is being accessed. Incompatibilities between the JDBC driver, the JRE, and the database server versions can impact application performance.- Use JDBC batch updates where possible: The JDBC API provides an addBatch() method to add SQL queries into a batch and an executeBatch() method to send batch queries for execution.JDBC batch updates can reduce the number of database roundtrips, which result in significant performance gain.
- Disable auto-commit mode when not required: When you are running statements in a batch, it is better to disable the auto-commit mode of a connection. This enables you to group SQL Statements in one transaction and commit them. Otherwise, as auto-commit mode is turned on by default, every SQL statement runs in its own transaction and commits as soon as it finishes.
- Use the NOLOCK hint or transaction isolation-level settings to enhance performance: Your application may have multiple users accessing it in parallel while also accessing URLs and causing queries to be issued to the database in parallel. If Microsoft SQL server is your database server, using the NOLOCK hint allows the database server to read data from tables by ignoring any locks, and therefore, not being blocked by other processes. This query also does not acquire any locks, and therefore, does not block other processes. If your application does not require strict synchronization across database reads and writes, you can set the NOLOCK hint in your queries. JDBC provides different transaction isolation levels that can be set at the database connection level. READ UNCOMMITTED is the transaction level, which provides for asynchronous read operations to the database.
2. Use Connection Pools for Database Access
| What is a database connection pool? A connection pool is a cache of database connection objects. The objects represent physical database connections that can be used by an application to connect to a database. At run time, the application requests a connection from the pool. |
With connection pooling, connections are reused (rather than being created) each time a connection is requested. The basic reason for having a database connection pool is that connection establishment is a time-consuming and expensive activity. If your database server is SSL-enabled, or uses Windows authentication, then it takes even more time to establish a connection. Here is a screenshot of eG Enterprise monitoring a Microsoft SQL database server. Notice that the time taken for connecting to this database server is 51 msecs but query execution time is only 1 msec. Establishing a connection and tearing it down can be more time-consuming and expensive than actually querying the database server. This is the issue that database connection pooling solves.

Notice the connection time is 51 msecs and query execution takes only 1 msec.

This reduces total response time.
Database connection pools have many configuration parameters. The initial pool size, the maximum pool size, the current pool size, the number of free and in-use connections in the pool are some of the key metrics to be tracked when monitoring database connection pools. For best performance, the database connection pool must be configured appropriately. For smaller workloads, keep the initial pool size as small as possible. If you are supporting a heavy workload and expect to see many connections in use, it is better to set the initial size to match the expected number of connections in use. Connection-pooling modules try to add new connections when required and remove them when they are not needed. Hence, setting the initial pool size to be as close to the number of connections you expect to need most of the time will give you the best performance.
| From a monitoring standpoint, track the usage of your database connection pool. If your usage ever gets close to 100%, it means you have not sized your connection pool adequately, or you have a connection leak in your application. |

3. Make Sure to Close Database Objects After Use
There are different types of database objects that Java applications must deal with. After you establish a connection, you need to create a statement before you execute queries.
There are three types of JDBC statements:
- Statement
- Prepared Statement, and
- Callable statement.
While a statement is used to execute a static query, a prepared statement represents a precompiled SQL statement that can be executed multiple times.
A callable statement is used to call a stored procedure with parameters. Once you have created a statement, you can execute a query. The results of a query are accessible to the application using ResultSets.

While you can write applications that use database objects, you must make sure that you explicitly close Statements and ResultSets when you no longer need them.
In the example on the right, database resources are not closed after use. When objects remain unclosed while the application has moved on, the database server has not. It still has these objects available for use by the applications. These objects take up database server resources. As the database server has a finite amount of resources, if your applications keeps failing to close database objects repeatedly, it can slow down the database server and ultimately result in failures when another application or instance attempts to get a Connection, Statement, or a ResultSet.

Statements, ResultSets, and Connections extend AutoCloseable in JDK 7 and higher versions. If you declare a database resource in a try-with-resources statement and there is an error that the code does not catch, the JRE will attempt to close the connection automatically. This is a foolproof way of avoiding database resource issues caused by your application logic.
| From a monitoring standpoint, track the connections to the database server. Also, monitor other database resources, such as cursor usage. If cursor usage reaches the maximum configured limit for the database server, applications accessing the database server will see errors. If your cursor usage suddenly grows, one or more applications using the database server may not be closing Statements or ResultSets. |
4. Choose the Proper Statement Types to Use
As indicated, there are three types of statement objects that a Java developer can use.
| Statement vs. PreparedStatement: A Statement is for executing a specific SQL query and it can’t accept input parameters. A PreparedStatement is used for executing a parameterized SQL query many times dynamically. Parameter values can be provided as inputs. |

Using the right type of statement, objects can make a big difference in the performance of your application. Here are two examples:
- If you are executing a query that has pre-specified values and you are going to execute it once, you should be using “Statement” objects. Using a PreparedStatement in this case can be detrimental to performance. A prepared statement is optimized for repeated execution with different parameters. Therefore, some of the processing done when it is created is unnecessary, if it is going to be used once and that too without any parameters.
 | To validate this point, we constructed select queries against a table with 10 mil rows in a Microsoft SQL database. JTDS 1.3.1 was used as the JDBC driver. A select query using Statement took between 9 and 11 msecs whereas the same query issued using PreparedStatements took between 25 and 33 secs. That’s a 3000-fold increase in response time seen by the user because the Java developer failed to use the proper Statement object! |
- At the same time, if you must execute a similar query multiple times with different values, you should consider using PreparedStatements. A Statement object causes the query to be compiled each time. Hence, repeated executions of Statement objects will be much slower than the use of a PreparedStatement with different parameters.
5. Make Sure that Queries Match Indexes in the Database
 When building queries, Java programmers are often interested in how to frame the query to get the desired results. Performance of the query is not a major concern initially. However, when the application is deployed in production, performance becomes an important consideration.
When building queries, Java programmers are often interested in how to frame the query to get the desired results. Performance of the query is not a major concern initially. However, when the application is deployed in production, performance becomes an important consideration.
When a query takes a long time, the response time seen by the user is high and this leads to reduced satisfaction and productivity. Hence, it is important that queries issued by a Java application to a database server are tuned for optimal performance. Tuning of a query involves making sure that the search criteria in the query matches one of the indexes associated with a table being queried in the database.
| What is a database index? A database index is a data structure that improves the speed of data retrieval operations in a database table at the cost of additional writes and storage space to maintain the index data structure. Indexes are used to quickly locate data without having to search every row in a database table each time a database table is accessed. Indexes can be created using one or more columns of a database table, providing the basis for both rapid random lookups and efficient access to ordered records. The whole point of having an index is to speed up search queries by essentially cutting down the number of records/rows in a table that need to be examined. |
When a Java application does not use an index of a table in the query being issued, it results in a full table scan in the database. A full table scan looks through all of the rows in a table–one by one–to find the data that a query is looking for. Obviously, this can cause very slow SQL queries, if you have a table with a lot of rows. Using an index helps prevent full table scans.
To identify queries that are inefficient or slow, you can use Java application performance monitoring tools, such as eG Enterprise. Using bytecode instrumentation, eG Enterprise agents track all queries from your application to the database server and can highlight time-consuming queries, which are good targets for optimization.
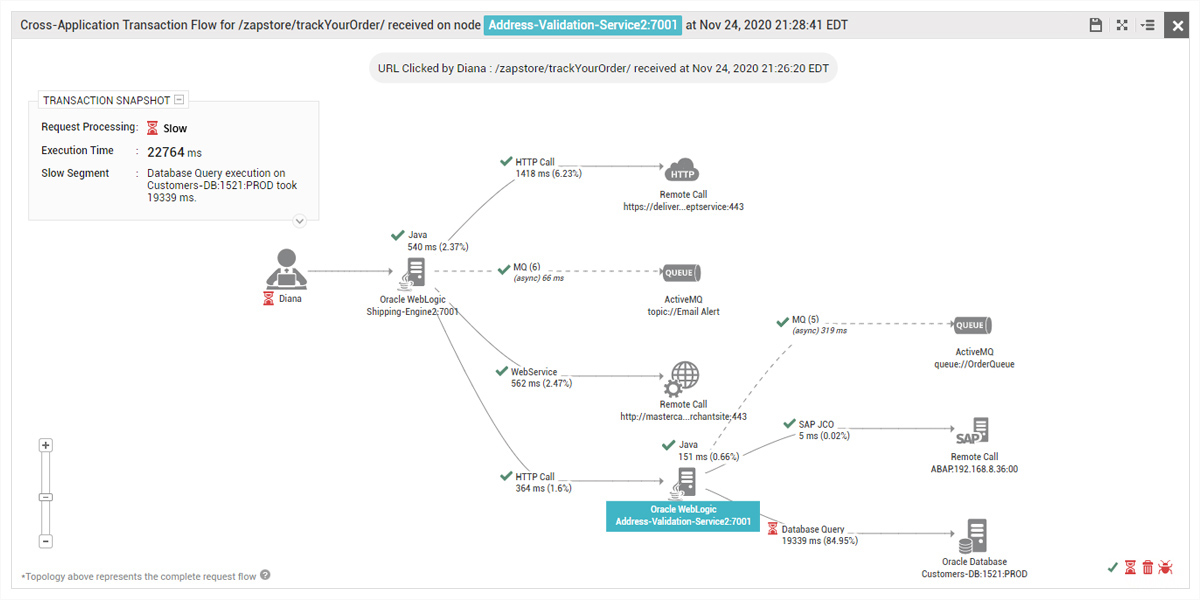


6. Cache Often Accessed Data
| What is caching? A cache is a memory buffer used to temporarily store frequently accessed data. It improves performance as data does not have to be retrieved again from the original source. |
 If your application is often accessing a large table in the database and if the table is not expected to change much, consider caching the data wherever possible–this can yield significant performance gains.
If your application is often accessing a large table in the database and if the table is not expected to change much, consider caching the data wherever possible–this can yield significant performance gains.
There are different forms of caching you can adopt. You can employ “in-process caching” wherein key data from the database is stored in the application memory. For large-scale applications, you may need to adopt “in-memory distributed caching” (see https://dzone.com/articles/introducing-amp-assimilating-caching-quick-read-fo).
There are many aspects you have to consider when implementing caching: when is data loaded, when is it updated, how much of the data can be in the cache, what is the eviction policy, how is concurrent access handled without introducing locks, etc.
Open-source cache APIs, such as Google Guava or commercial products, such as Coherence, Ehcache, or Hazelcast can also be considered.
| Note: Java application performance tuning is not just about JDBC access alone. Make sure that you are monitoring and tuning your JVM threads, heap memory configuration, garbage collection settings, etc. |
Conclusion
In this blog, we have discussed six key areas regarding database access that Java developers must consider as they develop and optimize their applications for production deployment.
At the same time, consider adding monitoring capabilities in your application (through log files, REST APIs, etc.). This can go a long way towards making your applications easier to manage and reduce the time that you spend in troubleshooting “why is your application slow?”.
eG Enterprise is an Observability solution for Modern IT. Monitor digital workspaces,
web applications, SaaS services, cloud and containers from a single pane of glass.



