AWS Application Load Balancers Test
An AWS Application Load Balancer serves as the single point of contact for clients. The load balancer distributes incoming application traffic across multiple targets, such as EC2 instances, Lambda functions etc., in multiple Availability Zones. This increases the availability of your application.
Figure 1 depicts how the load balancer works.
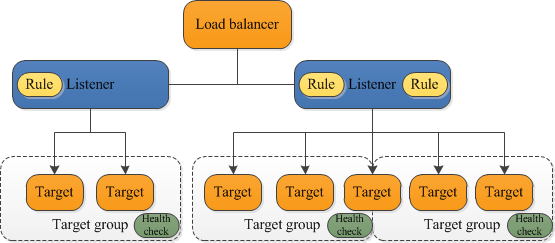
Figure 1 : How does the load balancer work?
Typically, listeners configured on the load balancer check for connection requests from applications. When a connection is received, rules defined in the listener dictate how load is routed to targets in a target group and the order in which the rules are to be applied on the targets.
If the load balancer is unavailable or error-prone, then applications will be denied access to critical cloud services such as EC2 instances, Lambda functions etc. This can adversely impact user experience with the applications. Likewise, if the load balancer is not configured with the right routing rules, then the request load will not be uniformly balanced across the targets in the Availability zones. This again can degrade application performance. Furthermore, if you do not size the load balancer with capacity units or count of listeners in keeping with the volume of application traffic, the processing power of the load balancer will be severely compromised.
Therefore, to ensure the continuous availability and peak performance of the applications, administrators should ensure that the AWS application load balancers are up and running at all times, are configured right, and process requests in a swift, uniform, and error-free manner. The AWS Application Load Balancers test helps administrators achieve all of the above!
For each AWS Application Load Balancer, this test reports the current state of that load balancer. The load balancers in an abnormal state can thus be isolated. Alerts are sent out if any load balancer encounters HTTP errors or connection errors. This enables administrators to investigate and fix those errors, before load balancing is crippled. Requests per target and average responsiveness of the targets are measured for every load balancer. This way, administrators can determine if the targets of any load balancer are responding poorly to requests. The routing rules and configuration of such a load balancer should then be scrutinized and reset (if required) to improve target responsiveness.
Target of the test: Amazon Cloud
Agent deploying the test: A remote agent
Output of the test: One set of results for each Application Load Balancer configured for the target AWS account
| Parameter | Description |
|---|---|
|
Test Period |
How often should the test be executed. |
|
Host |
The host for which the test is to be configured. |
|
Access Type |
eG Enterprise monitors the AWS cloud using AWS API. By default, the eG agent accesses the AWS API using a valid AWS account ID, which is assigned a special role that is specifically created for monitoring purposes. Accordingly, the Access Type parameter is set to Role by default. Furthermore, to enable the eG agent to use this default access approach, you will have to configure the eG tests with a valid AWS Account ID to Monitor and the special AWS Role Name you created for monitoring purposes.
Some AWS cloud environments however, may not support the role-based approach Note that the Secret option may not be ideal when monitoring high-security cloud environments. This is because, such environments may issue a security mandate, which would require administrators to change the Access Key and Secret Key, often. Because of the dynamicity of the key-based approach, Amazon recommends the Role-based approach for accessing the AWS API. |
|
AWS Account ID to Monitor |
This parameter appears only when the Access Type parameter is set to Role. Specify the AWS Account ID that the eG agent should use for connecting and making requests to the AWS API. To determine your AWS Account ID, follow the steps below:
|
|
AWS Role Name |
This parameter appears when the Access Type parameter is set to Role. Specify the name of the role that you have specifically created on the AWS cloud for monitoring purposes. The eG agent uses this role and the configured Account ID to connect to the AWS Cloud and pull the required metrics. To know how to create such a role, refer to Creating a New Role. |
|
AWS Access Key, AWS Secret Key, Confirm AWS Access Key, Confirm AWS Secret Key |
These parameters appear only when the Access Type parameter is set to Secret.To monitor an Amazon instance, the eG agent has to be configured with the access key and secret key of a user with a valid AWS account. For this purpose, we recommend that you create a special user on the AWS cloud, obtain the access and secret keys of this user, and configure this test with these keys. The procedure for this has been detailed in the Obtaining an Access key and Secret key topic. Make sure you reconfirm the access and secret keys you provide here by retyping it in the corresponding Confirm text boxes. |
|
Proxy Host and Proxy Port |
In some environments, all communication with the AWS cloud and its regions could be routed through a proxy server. In such environments, you should make sure that the eG agent connects to the cloud via the proxy server and collects metrics. To enable metrics collection via a proxy, specify the IP address of the proxy server and the port at which the server listens against the Proxy Host and Proxy Port parameters. By default, these parameters are set to none , indicating that the eG agent is not configured to communicate via a proxy, by default. |
|
Proxy User Name, Proxy Password, and Confirm Password |
If the proxy server requires authentication, then, specify a valid proxy user name and password in the proxy user name and proxy password parameters, respectively. Then, confirm the password by retyping it in the CONFIRM PASSWORD text box. By default, these parameters are set to none, indicating that the proxy sever does not require authentication by default. |
|
Proxy Domain and Proxy Workstation |
If a Windows NTLM proxy is to be configured for use, then additionally, you will have to configure the Windows domain name and the Windows workstation name required for the same against the proxy domain and proxy workstation parameters. If the environment does not support a Windows NTLM proxy, set these parameters to none. |
|
Exclude Region |
Here, you can provide a comma-separated list of region names or patterns of region names that you do not want to monitor. For instance, to exclude regions with names that contain 'east' and 'west' from |
|
Default Connection Region |
By default, this test connects to the endpoint URL of the us-east-1 region to collect the required metrics. If the default us-east-1 region is not enabled in the target environment, then, for this test to collect the required metrics, specify the region that is enabled in the target environment. |
|
DD Frequency |
Refers to the frequency with which detailed diagnosis measures are to be generated for this test. The default is 1:1. This indicates that, by default, detailed measures will be generated every time this test runs, and also every time the test detects a problem. You can modify this frequency, if you so desire. Also, if you intend to disable the detailed diagnosis capability for this test, you can do so by specifying none against DD frequency. |
|
Detailed Diagnosis |
To make diagnosis more efficient and accurate, the eG Enterprise embeds an optional detailed diagnostic capability. With this capability, the eG agents can be configured to run detailed, more elaborate tests as and when specific problems are detected. To enable the detailed diagnosis capability of this test for a particular server, choose the On option. To disable the capability, click on the Off option. The option to selectively enable/disable the detailed diagnosis capability will be available only if the following conditions are fulfilled:
|
|
Measurement |
Description |
Measurement Unit |
Interpretation |
|||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
Listeners |
Indicates the number of listeners configured for this load balancer. |
Number |
A listener checks for connection requests, using the protocol and port that you configure. The rules that you define for a listener determine how the load balancer routes requests to its registered targets. By default, you can configure a maximum of 50 listener for a load balancer. You can however increase this count based on the current and anticipated connection load on the load balancer. Use the detailed diagnosis to know which listeners are configured on the load balancer, the security policies and actions defined for every listener, and the SSL certificate of each listener. |
|||||||||||||||
|
Healthy instances |
Indicates the number of targets of this load balancer that are healthy. |
Number |
Each load balancer node periodically sends requests to its registered targets to test their status. These tests are called health checks. These checks are conducted using the health check settings that are configured for the target groups with which a target is registered. After your target is registered, it must pass one health check to be considered healthy. A non-zero value for this measure means one/more registered targets have passed at least one health check. Ideally therefore, the value of this measure should be high. Use the detailed diagnosis of this measure to identify the healthy targets and the target groups they belong to. |
|||||||||||||||
|
Unhealthy instances |
Indicates the number of targets of this load balancer that are unhealthy. |
Number |
Each load balancer node periodically sends requests to its registered targets to test their status. These tests are called health checks. These checks are conducted using the health check settings that are configured for the target groups with which a target is registered. After your target is registered, it must pass one health check to be considered healthy. Likewise, if a target fails a configured number of consecutive health checks, then that target will be considered 'Unhealthy'. A non-zero value for this measure hence means that one/more targets registered with a load balancer are consistently failing health checks. This is a cause for concern. In such a scenario, use the detailed diagnosis of this measure to know which targets are unhealthy, which target groups they belong to, and why their health checks failed. This should help you troubleshoot the failures quickly and effectively. Here are some possible reasons for health check failures and how to fix them:
|
|||||||||||||||
|
Active TCP connections |
Indicates the total number of concurrent TCP connections active from clients to this load balancer and from this load balancer to targets. |
Number |
This is a good indicator of the connection load on the load balancer. The value of this measure averaged over a minute is considered for computing the capacity units (LCUs) consumed by the load balancer. These capacity units are in turn used for calculating your hourly Application Load Balancer usage costs. |
|||||||||||||||
|
New connections |
Indicates the total number of TCP connections from and to this load balancer during the last measurement period. |
Number |
The value of this measure averaged over a second is considered for computing the capacity units (LCUs) consumed by the load balancer. These capacity units are in turn used for calculating your hourly Application Load Balancer usage costs. |
|||||||||||||||
|
Rejected connections |
Indicates the number of connections that were rejected because this load balancer had reached its maximum number of connections. |
Number |
Ideally, the value of this measure should be 0. |
|||||||||||||||
|
Requests |
Indicates the total number of requests processed by this load balancer over IPv4 and IPv6. |
Number |
This is a good indicator of the workload of the load balancer. This metric is only incremented for requests where the load balancer node was able to choose a target. Requests that are rejected before a target is chosen are not reflected in this metric. |
|||||||||||||||
|
Rule evaluations |
Indicates the number of rules processed by the load balancer given a request rate averaged over an hour. |
Number |
A non-zero value is desired for this measure. The value of this measure averaged over a second is considered for computing the capacity units (LCUs) consumed by the load balancer. These capacity units are in turn used for calculating your hourly Application Load Balancer usage costs. |
|||||||||||||||
|
Processed data by load balancer |
Indicates the total number of bytes processed by this load balancer over IPv4 and IPv6. |
MB |
The value of this measure in GB is considered for computing the capacity units (LCUs) consumed by the load balancer. These capacity units are in turn used for calculating your hourly Application Load Balancer usage costs. |
|||||||||||||||
|
Consumed capacity |
Indicates the number of load balancer capacity units (LCU) used by this load balancer. |
Number |
Typically, AWS charges you for each hour or partial hour that an Application Load Balancer is running, and the number of Load Balancer Capacity Units (LCU) used per hour. An LCU measures the dimensions on which the Application Load Balancer processes your traffic (averaged over an hour). The four dimensions measured are:
You are charged only on the dimension with the highest usage. An LCU contains:
You may want to keep an eye on the value of this measure to understand your Application load balancer usage. Sudden, significant spikes in this measure value may require investigation. Under such circumstances, its best to track changes to the values of the Active connections, New connections, Rule evaluations. and Processed data by load balancer measures as well. As these measures influence the LCU, knowledge of these measure dynamics may provide pointers to where the major resource spend is. |
|||||||||||||||
|
IPv6 requests received by load balancer |
Indicates the total number of requests processed by this load balancer over IPv6. |
Number |
|
|||||||||||||||
|
IPV6 processed data by load balancer |
Indicates the total number of bytes processed by the load balancer over IPv6. |
Number |
|
|||||||||||||||
|
Request count per target |
Indicates the average number of requests received by each target in the target groups configured for this load balancer. |
Number |
Use the detailed diagnosis of this measure to know how many requests were received by each target group. This will point you to those target groups with the maximum number of requests. |
|||||||||||||||
|
Target response time |
Indicates the time elapsed, in seconds, after the request leaves the load balancer until a response from the target is received. |
Seconds |
A consistent increase in the value of this measure is a cause for concern. Here are some possible causes for poor responsiveness and their probable resolutions:
|
|||||||||||||||
|
Target TLS negotiation errors |
Indicates the number of TLS connections initiated by this load balancer that did not establish a session with the target due to a TLS error. |
Number |
Ideally, the value of this measure should be 0. A non-zero value is a cause for concern, as it implies that one/more connections failed owing to TLS errors. Possible causes include a mismatch of ciphers or protocols or the client failing to verify the server certificate and closing the connection. |
|||||||||||||||
|
Target connection errors |
Indicates the number of connections that were not successfully established between this load balancer and its targets. |
Number |
Ideally, the value of this measure should be 0. A non-zero value is a cause for concern, as it implies that one/more targets are unreachable. The primary cause for connection errors is that the target is overloaded and rejecting new connections. If the increased connection errors coincides with an increase in the request rate to a target, then this is the likely culprit. Another common cause for connection errors is that traffic is being routed to a port specified in the load balancer’s listener that a target is not listening to. This can happen if the process listening on the expected port dies unexpectedly, or if a firewall or security group is not allowing access on the port. If the health check port is different than the listener port, it is possible for this to occur even when the health checks succeed. |
|||||||||||||||
|
Client TLS negotiation error |
Indicates the number of TLS connections initiated by the client that did not establish a session with this load balancer due to a TLS error. |
Number |
Ideally, the value of this measure should be 0. A non-zero value is a cause for concern, as it implies that one/more connections failed owing to TLS errors. Possible causes include a mismatch of ciphers or protocols or the client failing to verify the server certificate and closing the connection. |
|||||||||||||||
|
HTTP 4xx client errors |
Indicates the number of HTTP 4XX client error codes that originate from this load balancer. |
Number |
Client errors are generated when requests are malformed or incomplete. These requests were not received by the target, other than in the case where the load balancer returns an HTTP 460 error code. This count does not include any response codes generated by the targets. |
|||||||||||||||
|
HTTP 5xx server errors |
Indicates the number of HTTP 5XX server error codes that originate from this load balancer. |
Number |
5xx errors are server errors—meaning the server encountered an issue and is not able to serve the client's request. This count does not include any response codes generated by the targets. |
|||||||||||||||
|
HTTP 2xx response code |
Indicates the number of HTTP 2xx response codes generated by the targets of this load balancer. |
Number |
This class of status code indicates that the targets have successfully received, understood, and accepted the requests. |
|||||||||||||||
|
HTTP 3xx response code |
Indicates the number of HTTP 3xx response codes generated by the targets of this load balancer. |
Number |
This class of status code indicates the targets must take additional action to complete the request. Many of these status codes are used in URL redirection. |
|||||||||||||||
|
HTTP 4xx response code |
Indicates the number of HTTP 4XX error codes generated by the targets of this load balancer. |
Number |
4xx response codes indicate error conditions. Therefore, the value of this measure should ideally be 0. |
|||||||||||||||
|
HTTP 5XX response code |
Indicates the number of HTTP 5XX error codes generated by the targets of this load balancer. |
Number |
5xx response codes indicate error conditions. Therefore, the value of this measure should ideally be 0. |
|||||||||||||||
|
State |
Indicates the current state of this load balancer. |
Number |
The values that this measure can report and the state they represent are detailed in the table below:
|
|||||||||||||||
|
Other targets |
Indicates the number of targets of this load balancer that are neither in a healthy nor in an unhealthy state. |
Number |
If this measure reports a non-zero value, it could imply that one/more targets are in one of the following states:
You can use the detailed diagnosis of this measure to determine the exact state of the targets. |
|||||||||||||||
|
Lambda user error |
Indicates the number of requests sent by this load balancer to a Lambda function that failed because of an issue with the Lambda function. |
Number |
Possible causes for the Lambda user errors include:
In case this measure reports a non-zero value, then use the detailed diagnosis of this measure to identify the target groups that experienced the maximum number of Lambda user errors. To know why these errors occurred, check the error_reason field of the access log. |
|||||||||||||||
|
Lambda internal error |
Indicates the number of requests that this load balancer sent to a Lambda function that failed because of an issue internal to the load balancer or AWS Lambda. |
Number |
In case this measure reports a non-zero value, then use the detailed diagnosis of this measure to identify the target groups that experienced the maximum number of Lambda internal errors. To know why these errors occurred, check the error_reason field of the access log. |
|||||||||||||||
|
Lambda target processed data |
Indicates the total number of bytes processed by this load balancer for requests to and responses from a Lambda function. |
MB |
|
|||||||||||||||
|
Total target groups |
Indicates the total number of target groups managed by this load balancer. |
Number |
Use the detailed diagnosis of this measure to know which target groups are managed by this load balancer. |